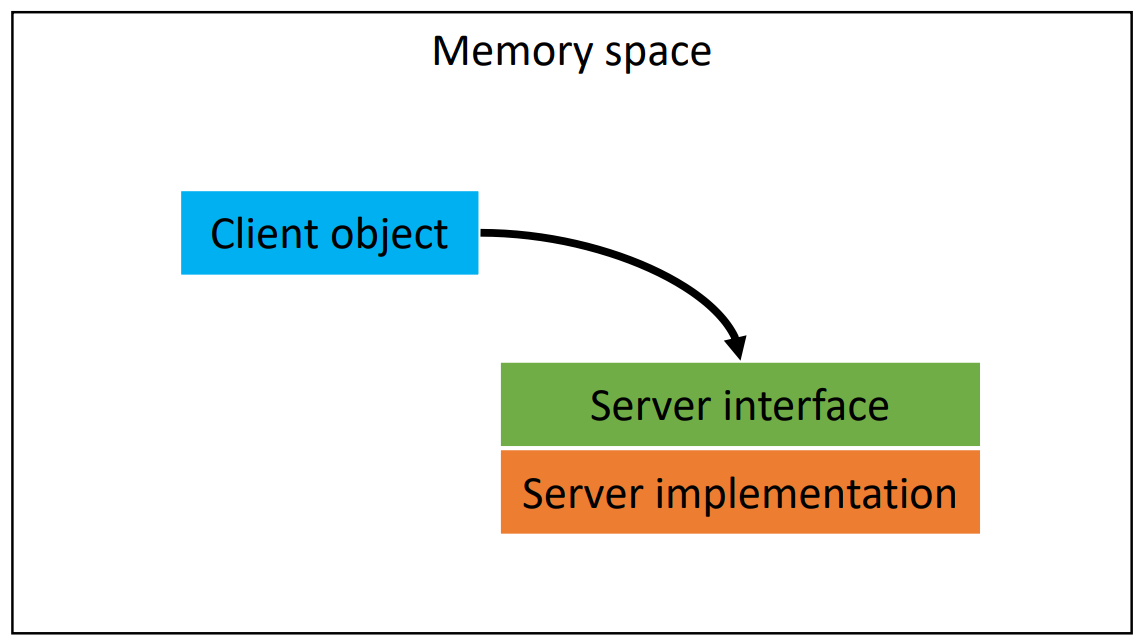
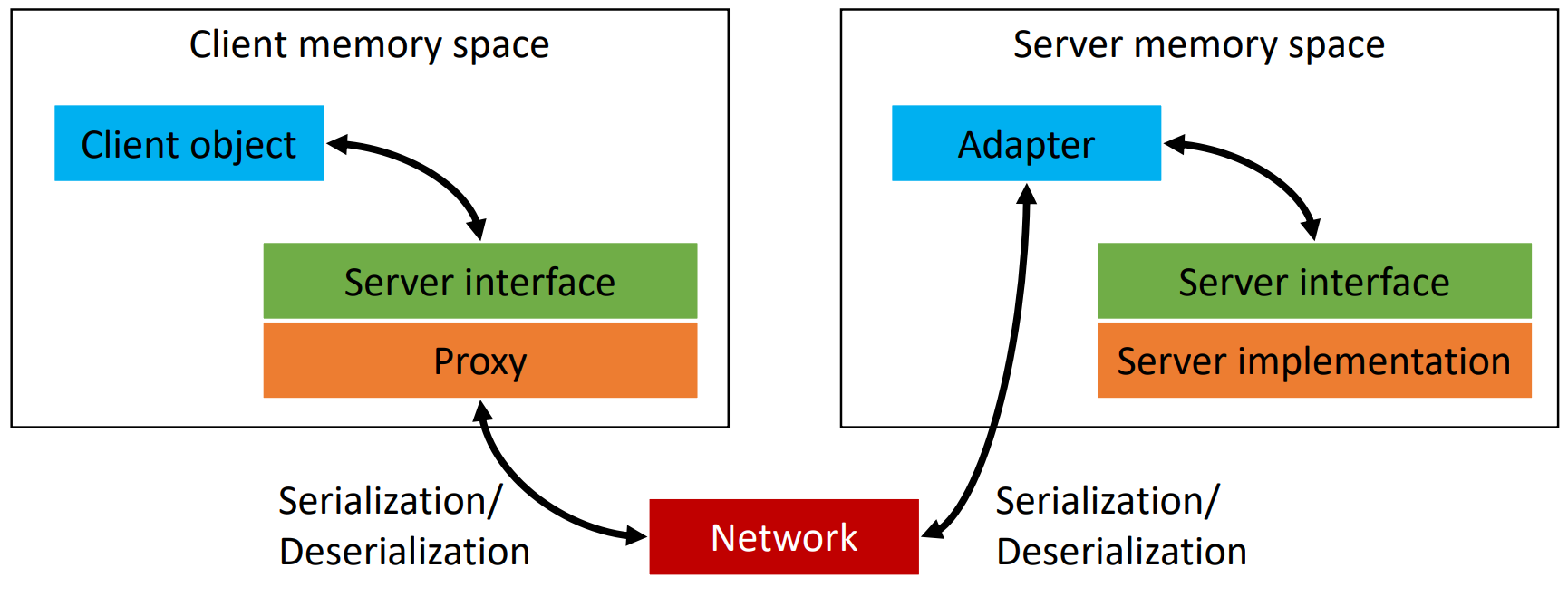
ugyanazon a programnyelven? → programnyelv interfészét használhatjuk
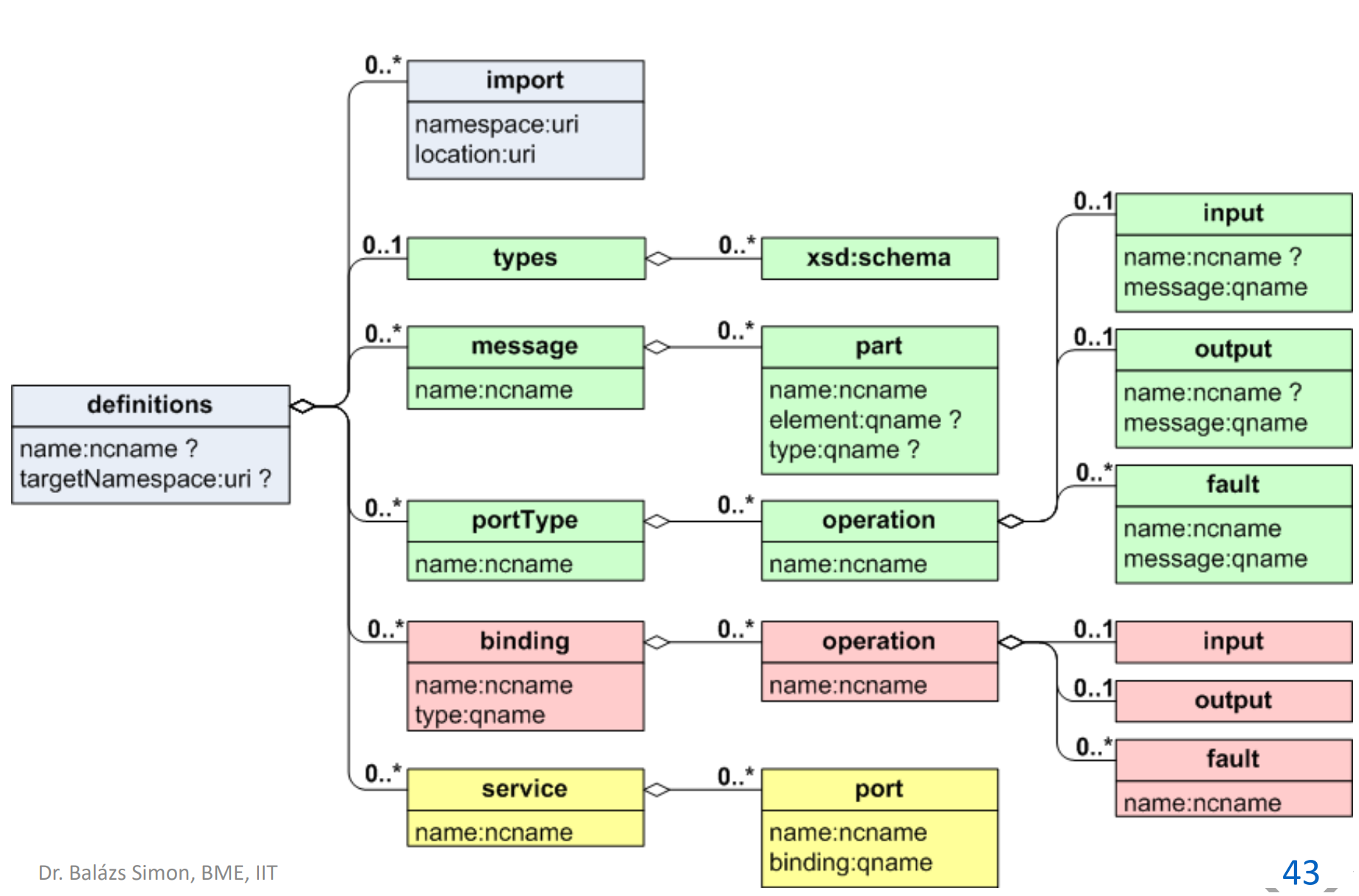
különböző programnyelven? → programnyelvektől független interfész leírókkal
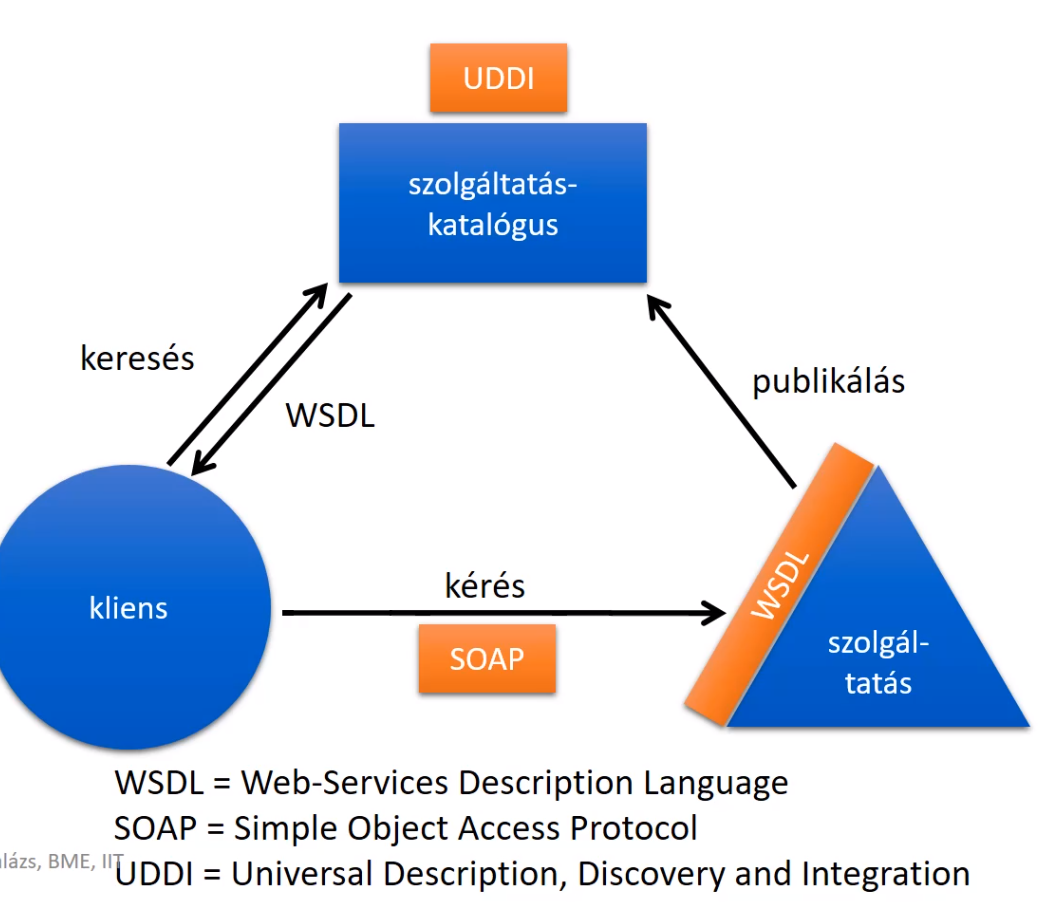
hogyan találjuk meg a szervert?
kliens tudja hol van → kliensnek config fájljában van
logikai név alapján → ezt a fordítást egy névszerver végzi
interfész alapján → treading service interfész specifikációból fizikai címet készít (pl időjáros cucc interfész kell)
hogyan implementáljuk a proxy-t?
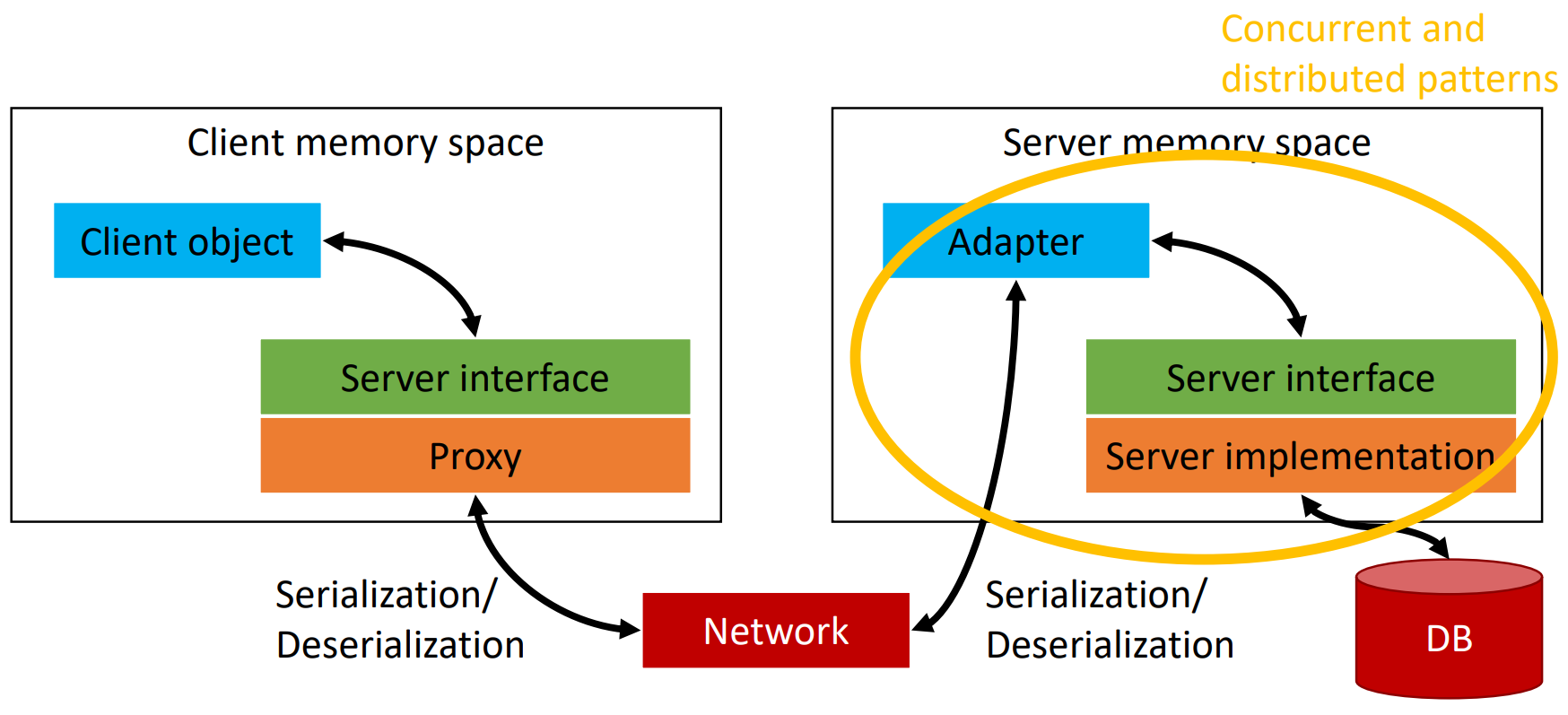
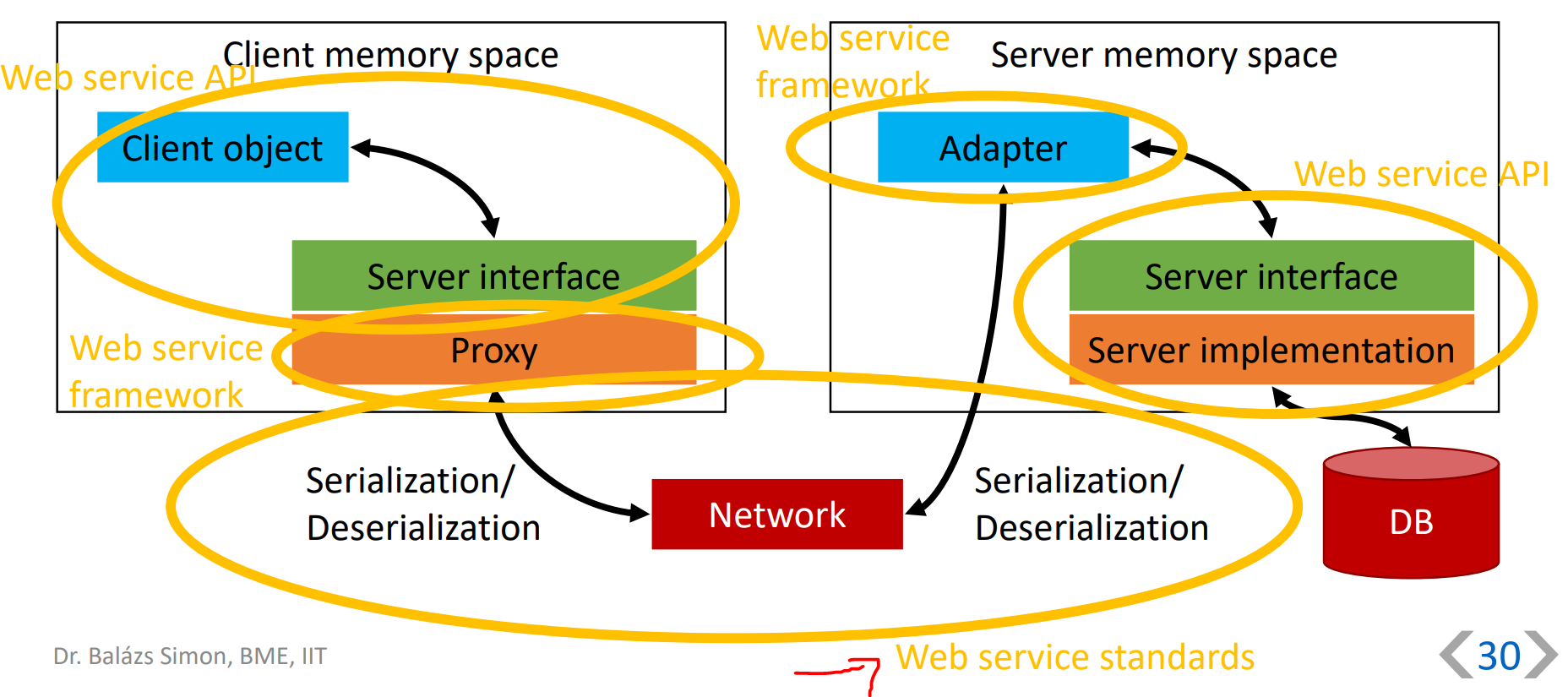
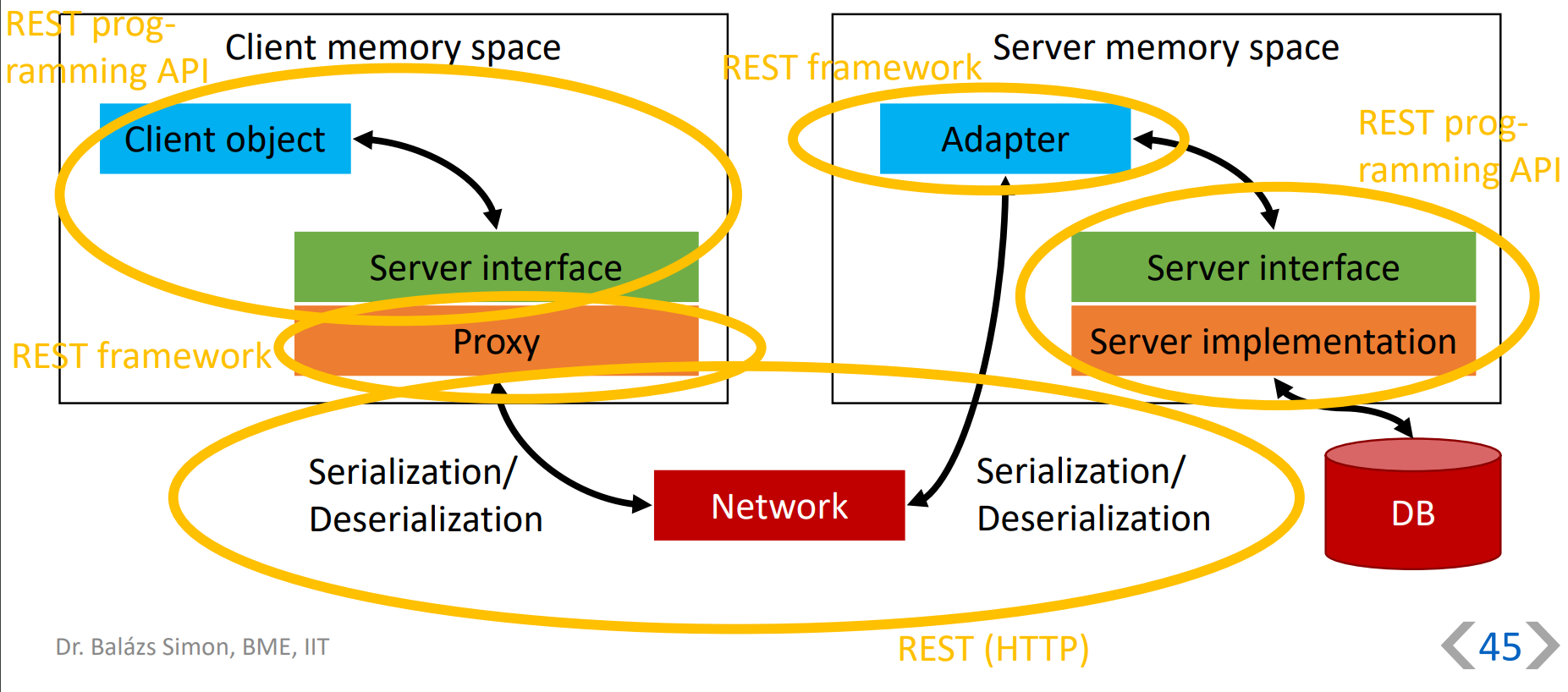
feladata: szerver megkeresése, kapcsolat felépítése, paraméterek és eredmények sorosítása
megvalósítás: proxy + adapter tervezési minta
hogyan implementáljuk az adaptert?
feladata: kliens kapcsolat fogadása, szerver objektum példányosítása, kliens kérdések továbbítása függvényhívásként a szerver objektumhoz, paraméterek és eredmények sorosítása, több kérdés kezelése párhuzamosan
megvalósítás: adapter tervezési minta
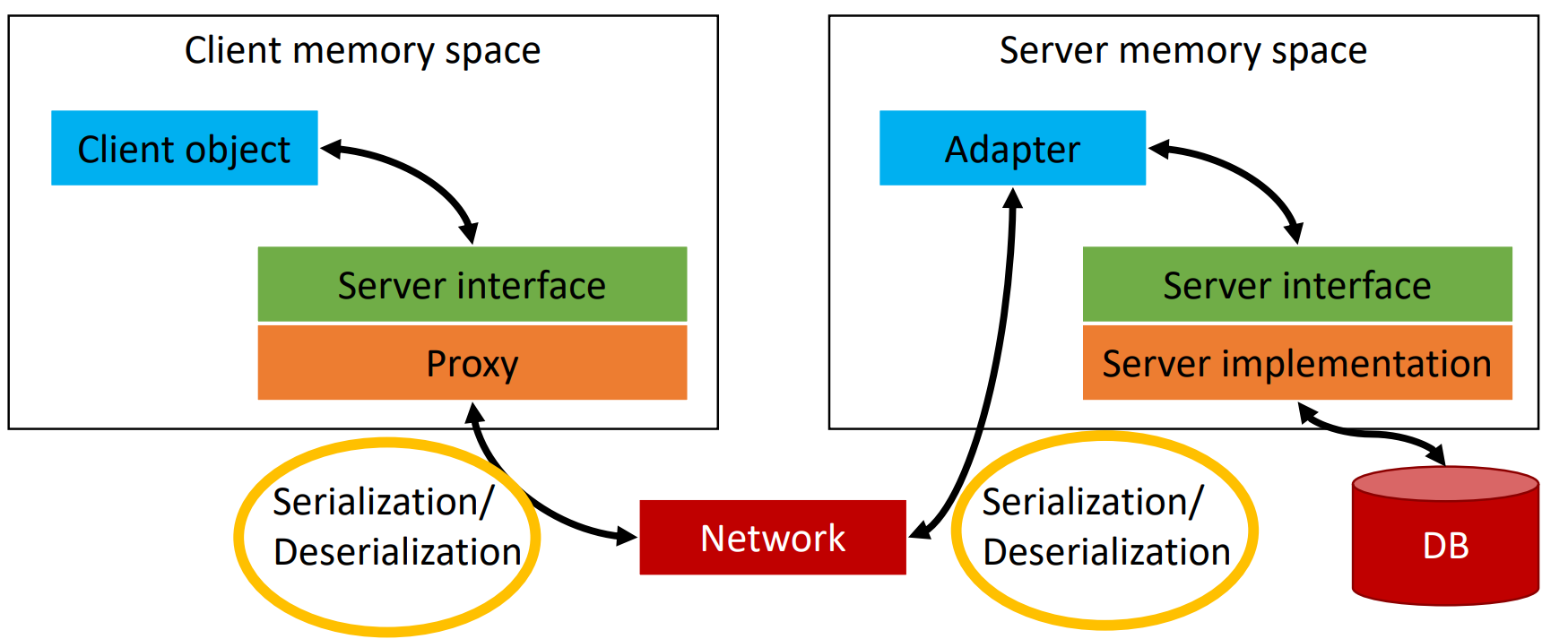
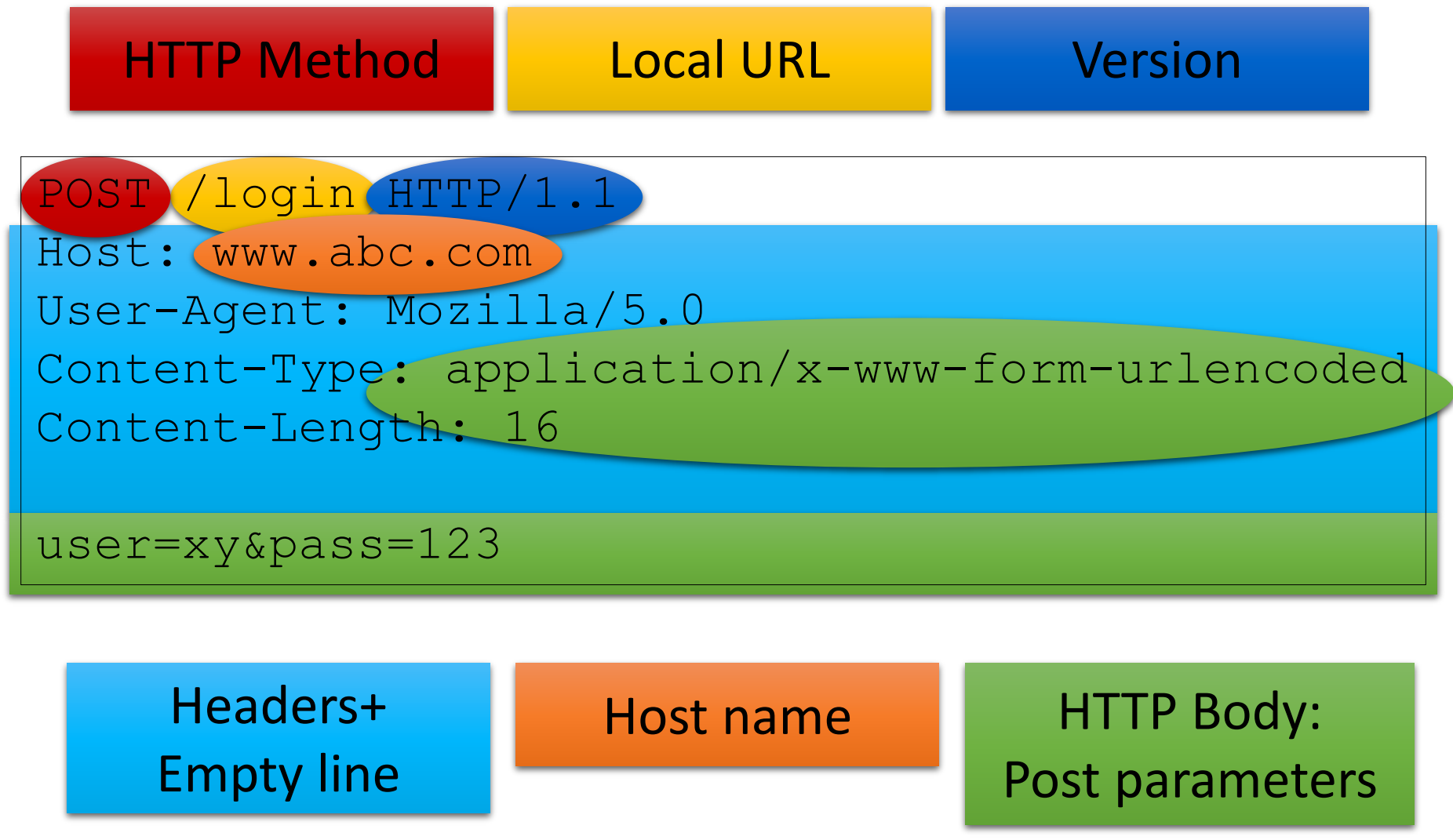
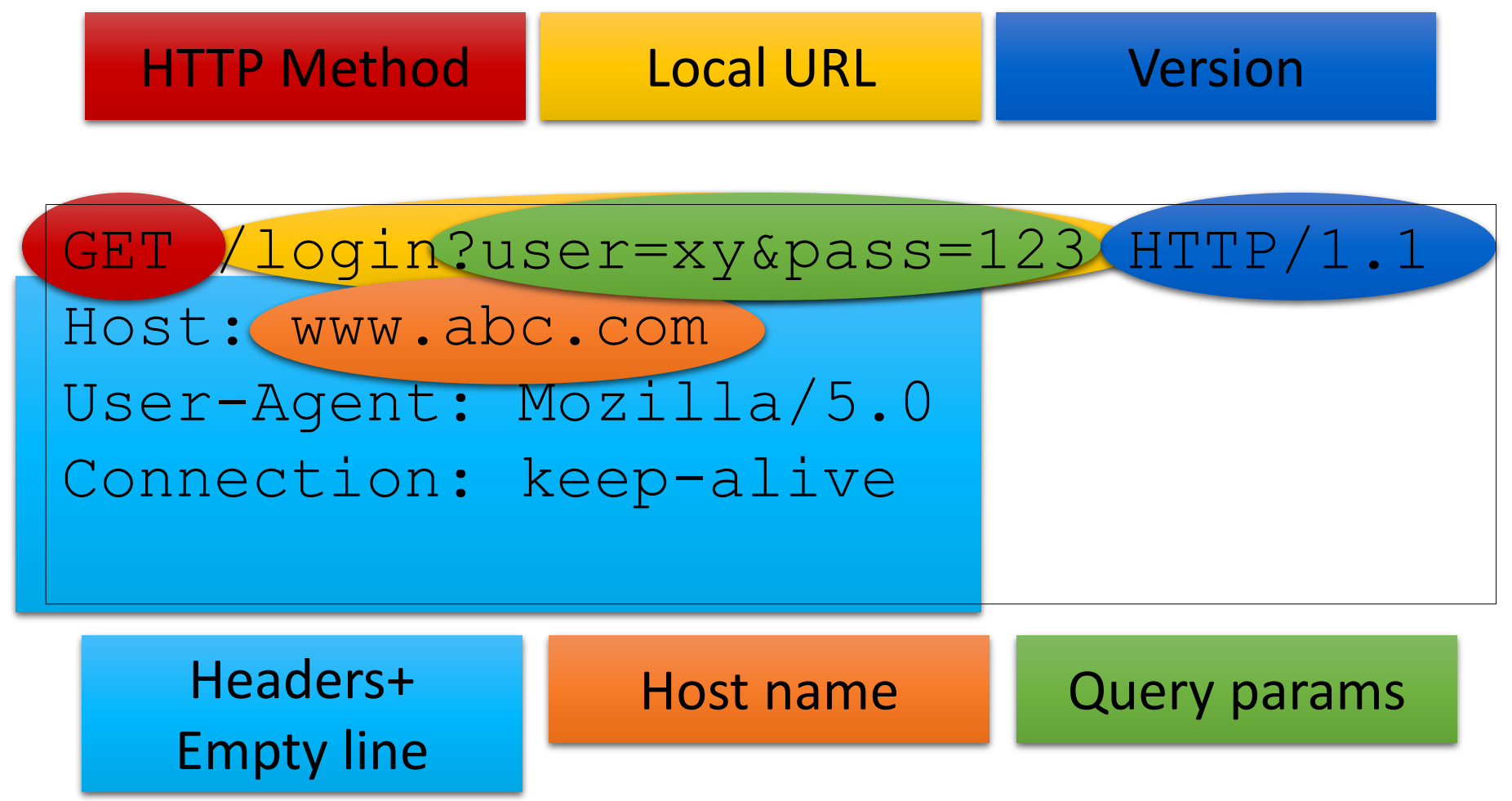
hogyan sorosítsuk az adatokat?
memóriában lévő adat bájtfolyammá és vissza
teljes hierarchiát kell leírni majd azt rekonstruálni a másik oldalon
2 fajta:
bináris sorosítás → gyors, hatékony, kevés memóriát használ, DE bináris kompatibilitást feltételez a kliens és szerver közt, pl ha ugyanazon programnyelven készültek
szöveges sorosítás → emberileg is olvasható (XML, JSON), lassabb, kevésbé hatékony, több memóriát eszik, DE programnyelvek közt kompatibilis, és időtálló
hogyan kezeljük a memóriát?
ki foglalja le és ki szabadítja fel a bemenő és kimenő paramétereket
modern nyelvekben: GC
régebbi nyelvekben: objektum tulajdonosának egyértelműsítésével
pl eredményt: proxy foglalja, kliens szabadítja
hogyan szolgálunk ki több klienst?
egy szálú szerver → nincs konkurencia probléma
blokkoló → újabb kéréseknek várakozni kell, míg a jelenlegi kiszolgálásra nem kerül (ilyet nem szoktunk csinálni → nem hatékony)
nem blokkoló → pl nodejs, hatékonyabb de komplex callback programozáson alapuló modellt igényel
több szálú szerver → védeni kell a több szál által használt adatokat
kliensként külön szál → könnyen túlterheli a szervert
thread pool → amíg van szabad szál, addig tud kiszolgálni, jól kihasználja a szerver erőforrásait
hány objektumpéldány kell a szerverből?
egy szerver példány → singleton, jó ha nincs kliens függő állapot
kliensenként egy → kliens specifikus állapotot is tud tárolni, DE nem skálázható (újrainduláskor elveszhet), lezáró szükséges
object pool → kiszolgáló szerver objktumokhoz rendeljük a klienseket, így kérések szeparálva futnak, de nincs kliens specifikus állapot. Ez jól skálázható
hogyan őrizzük meg az állapotot hívások között?
szerver memóriájában → minden kliens saját szerver objektum példánnyal rendelkezzen
minden hívásban átküldjük → működik, ha nem túl nagy ez az állapot (pl böngészú cookie-k)
adatbázisban → jól skálázódik, de a kliensnek azonosítani kell tudnia magát (kell seccion id)
hogyan kommunikáljunk, ha valamelyik oldal nem elérhető?
szinkron hívásnál (kliensnek azonnal kell válasz) → nem tudunk kommunikálni
aszinkron hívás (ráér a válasz)
ha nincs megbízható köztes szereplő
ha van megbízható köztes szereplő → megoldható a szétcsatolt kommunikáció (köztes szereplő vigyáz addig az adatra). Nehézség a visszaérkező válaszok párosítása a hozzájuk tartozó kérdésekkel
hogyan kezeljük a szinkron hívásokat?
általában folyamatosan fennálló kapcsolat kell
kliens elküldi a kérdést, blokkolva vár a válaszra
szerver fogadja a kérdést, és kiszolgálja:
szinkron módon
aszinkron módon
hogyan kezeljük az aszinkron hívásokat?
ha nincs megbízható köztes szereplő
call-back
periodikus pollozás
ha van megbízható köztes szereplő
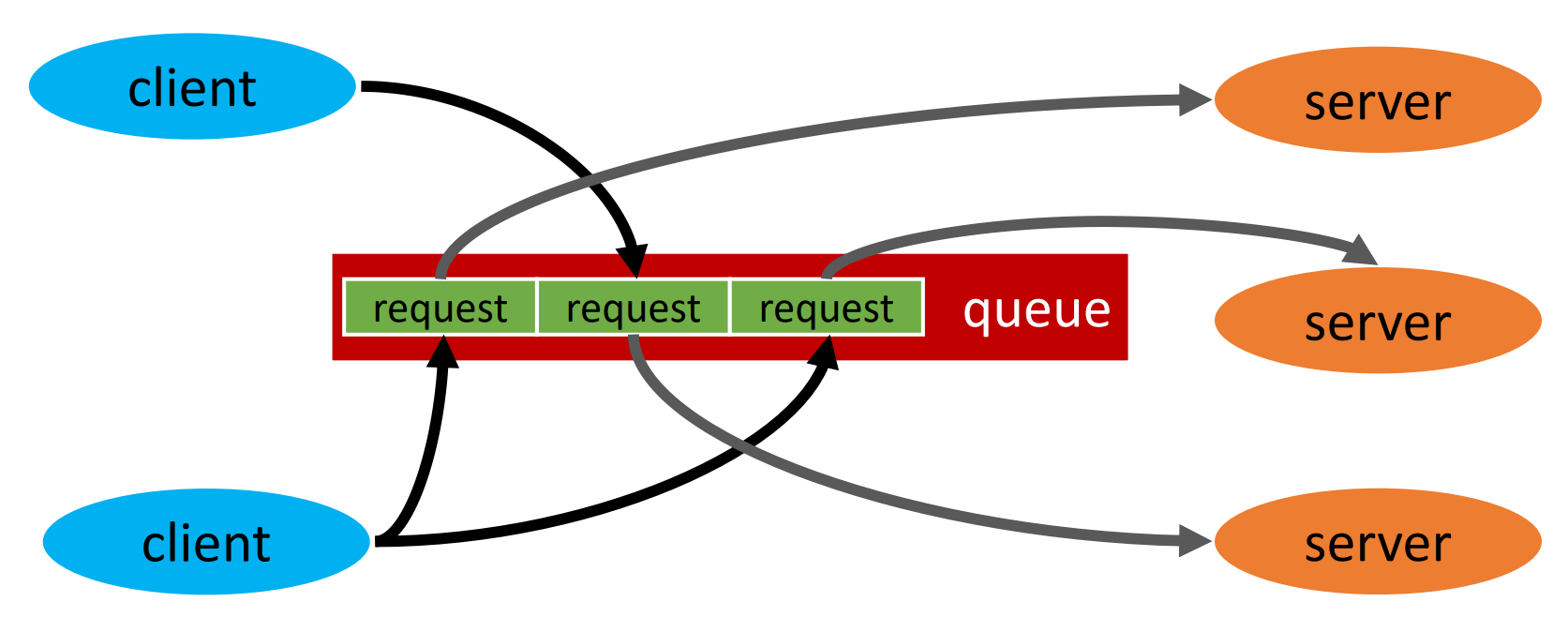
üzenetek: sok forrás (kliens), egy cél (szerver)
kliensek egy sorba küldik a kérdéseket, a szeverek meg ebből veszik ki
egy üzenetet csak egy szerverpéldány dolgozhat fel (más nem kaphatja meg)
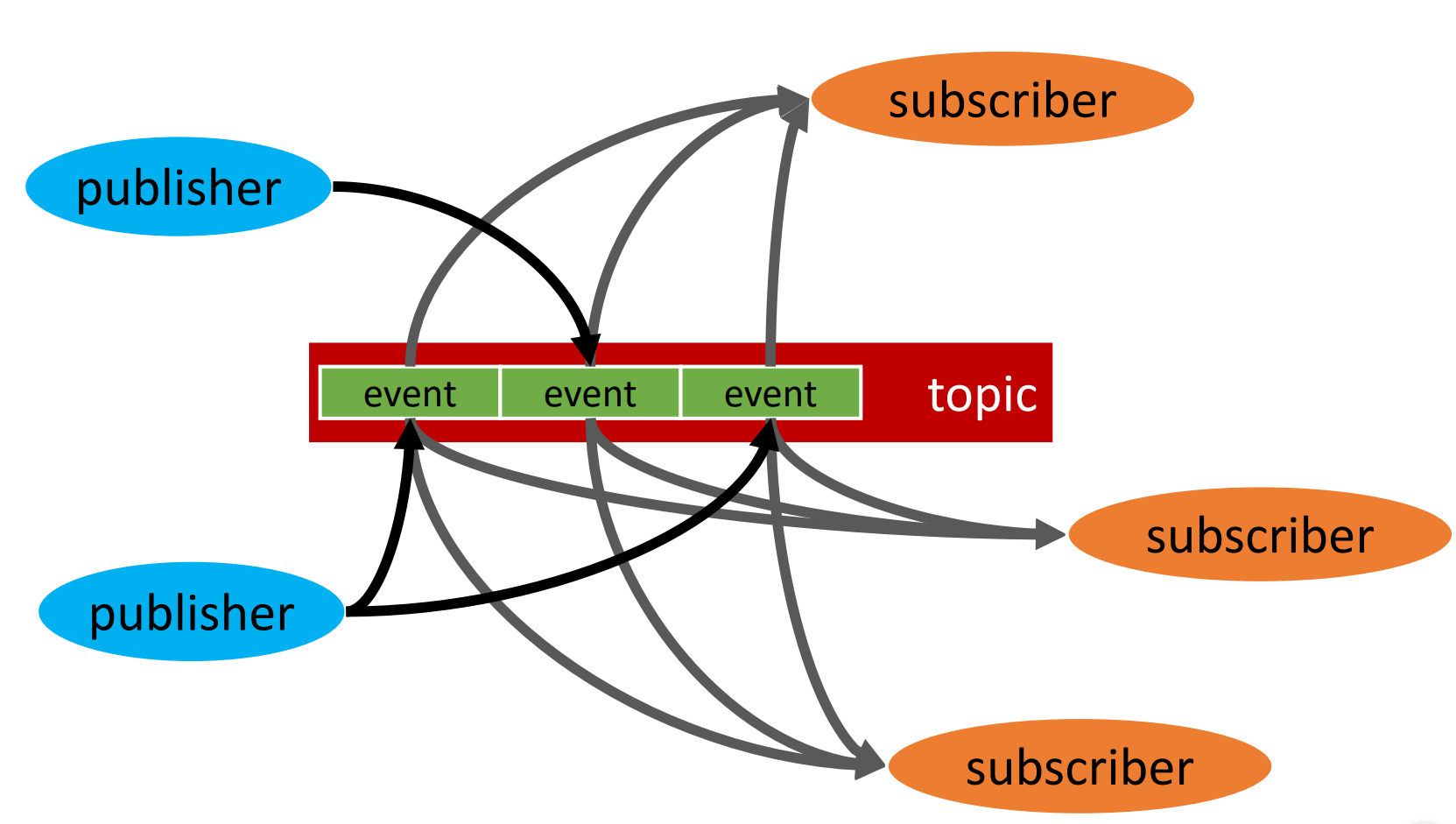
események: egy forrás (publisher), sok cél (subscriber)
minden eseményt minden feliratkozó megkap, és általában a fogadók nem küldenek választ