Adatvezérelt rendszerek¶
Bevezetés¶
- céljuk: Adat tárolása, és ezen adat elérhetővé tétele, adatot manipulálnak (a manipulációt befolyásolja maga az adat)
- adatvezérelt (data driven) -> pl: facebook, twitter, stackoverflow, neptun, booking.com, airbnb
- folyamatvezérelt (control driven) -> pl egy számítógépes játék
- félévben a példa → webshop
- fő adat: egy termék, vásárlás, számla
- megvannak a szabályok: mikor lehet rendelni, mikor megy át egy rendelés
Háromrétegű architektúra¶
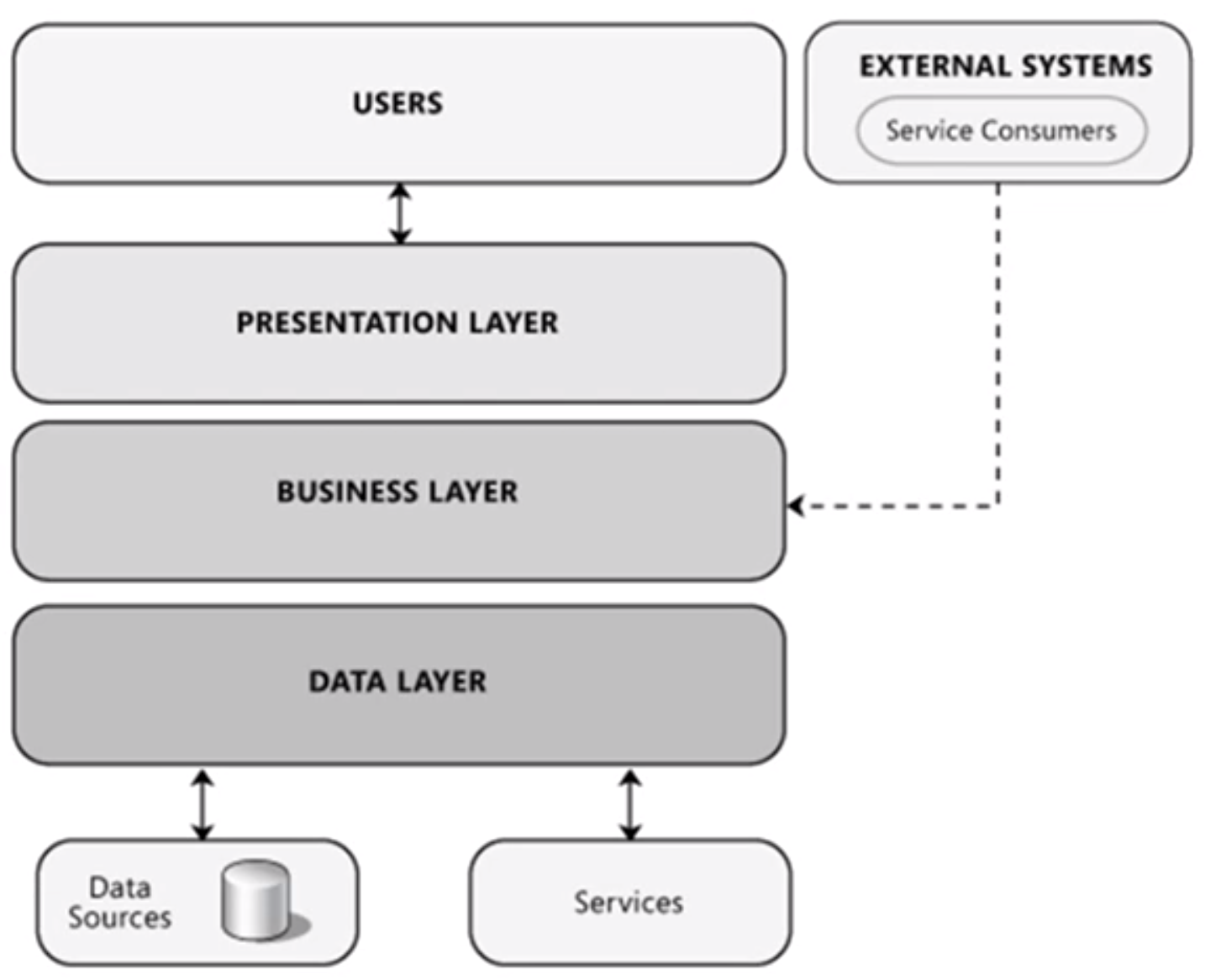
- Presentation Layer (Megjelenési réteg) → a UI, pl a holnap mint kezelőfelület
- Business Layer (Üzleti logikai réteg) → üzleti szabályok, pl csak oktató írhat be jegyet viszgaidőszakban
- Data Layer (Adat réteg) → perzisztens tárolás (adatbázisokban, de ebbe egyéb részek is beletartoznak)
- ezen rétegek sokszor külön gépen futnak, rétegek mentén szétbontva (layer - egy gépen fut, tier - több gépen fut)
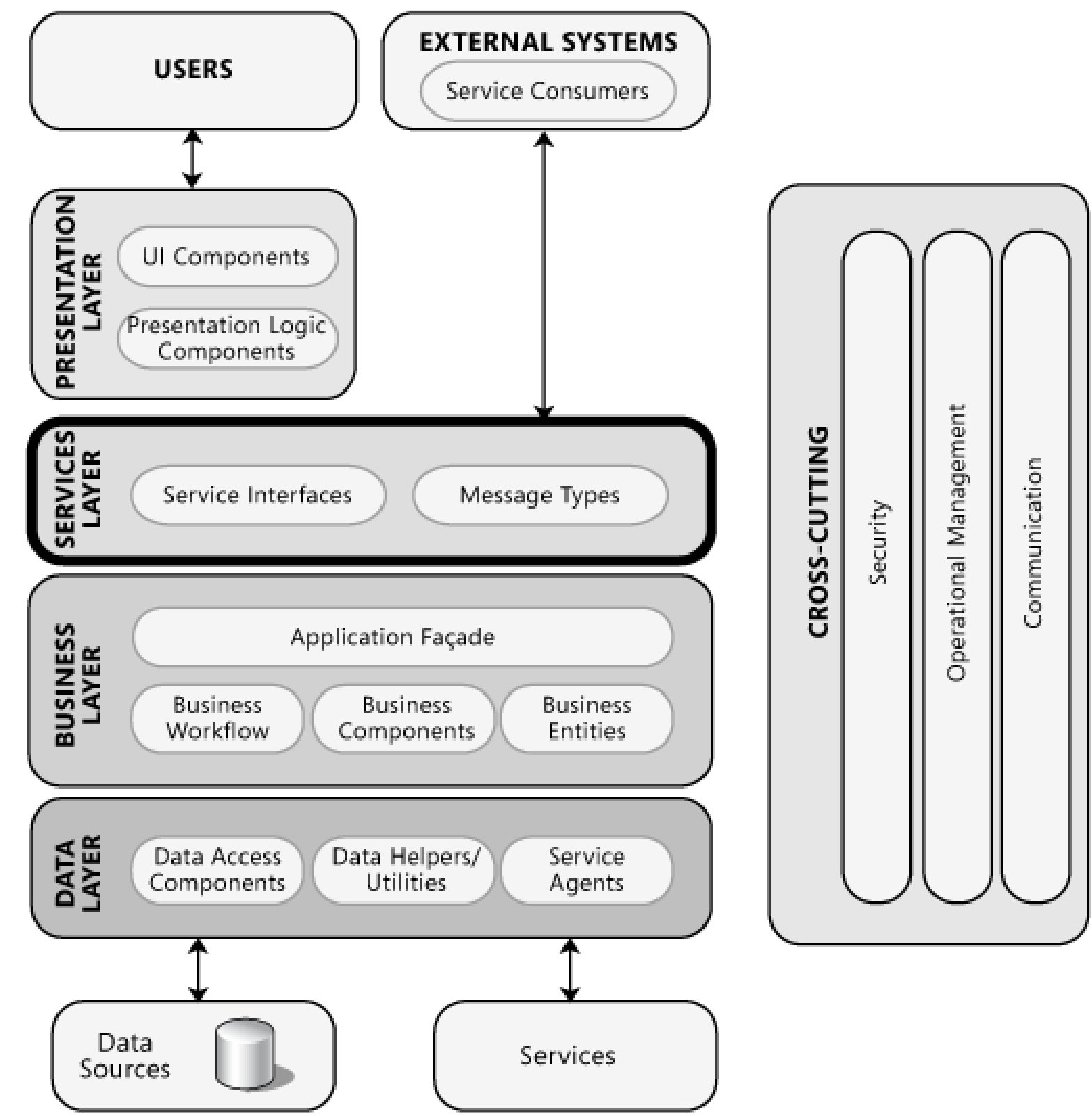
Data Layer - Adat réteg¶
- Perzisztenciáért felelnek → data source - adatforrás (pl relációs adatbázis, google drive)
- Akkor hívjuk Adat réteg-nek, ha nem tartalmazza az adatbázist
Data Access Layer - Adatelérési réteg¶
- Data Access Layer (Adatelérési réteg) → Ha az adatbázist vagy adatforrást is beleértjük
- pl csatoljuk hozzá ezt a fájlt az email-hez
- szolgáltatásként nyújtja az adatok manipulálásának módját
Business Layer - Üzletilogikai réteg¶
- Üzleti entitások (Business Entities) → főbb elemek, amiket manipulálunk (megrendelés, termék, kurzus, vizsga)
- Üzleti komponensek (Business Components) → egyszerűbb műveletek (pl vizsgajegy beírása - ezzel manipuláljuk a vizsgajegyet)
- Üzleti folyamtok (Business Workflow) → több lépéses, folyamatlépés folyamat (pl rendelés véglegesítése - sok lépésből áll, entitások halmazát manipuláljuk)
- Szolgáltatási interfész réteg (Services layer) → üzleti logika funkcióit a felhasználói réteg felé szolgáltatásként biztosítja (külön réteg, mert helyzetfüggő a megvalósítási módja)
Presentation layer - Megjelenítési réteg¶
- UI Components (Felhasználói felület komponensek) → pl weblap, asztali vagy mobil alkalmazás
- Presentation Logic Components (Megjelenési logikai komponensek) → pl keresés, szűrés
- feladatok:
- adatok értelmes megjelenítése
- egyéb funkcióra lehetőségek: keresés, szűrés
- lokalizáció (dátumok, pénzek, ezek felhasználó függően kerüljön kiírásra)
- a megjelenítési réteg nem nagyon gondolkozik, azt az üzletilogikai réteg csinálja
Cross-cutting - Rétegfüggetlen alkalmazások¶
- Minden rétegben megjelenő közös aspektusok:
- biztonság → bejelentkezés (aki belép, mit is csinálhat)
- operational management (üzemeltetés szolgáltatás) → naplózás, hibakeresés, audit naplózás (rögzítjük, hogy ki mit csinál a rendszerben), konfigurációkezelés, hibák naplózása
- kommunikáció → rétegek sokszor külön gépen vannak, ezek közt kommunikálni kell
- lehet szinkron és aszinkron is, adatbázissal általában szinkron, felhasználói felületről néha aszinkron
Összegzés¶
- backend → minden, ami a megjelenési réteg alatt van, a többi frontend
- sokszor kód szinten is megtörténik a szétválasztás
Tranzakciók¶
Konkurens adathozzáférés (az adatbázis tekintetében)¶
- Def: Egyazon adategységhez (pl egy tábla egy rekordja) egy időben többen férnek hozzá, és legalább egyikük módosítja.
Tranzakció fogalma¶
- A feldolgozás logikai egysége, olyan műveletek sorozata, melyek csak együttesen értelmesek
- Pl: rendelés véglegesítése → kosárban levő mind a 15 termékre raktárkészletet megnézni, csökkenteni az ottani számokat, elmenteni az adatbázisba, véglegesíteni
- Alaptulajdonságok:
- Atomicity (Atomi) → oszthatatlanság, a műveletek sorozatát egyben csináljuk végig, nem lehetnek részeredmények (vagy végig csinálja, vagy semmit nem csinál vele → atomi, oszthatatlan)
- Consistency (Konzisztencia) → konzisztens állapotból konzisztensbe megy (közben érinthet inkonzisztenst)
- Isolation (Izoláció) → úgy tud végig menni a műveletek sorozatán, mintha a rendszerben egyedül lenne (a rendszer biztosítja, hogy az átlapolódásból ne legyen baj)
- T1(A = 12, C = A+2), T2(A = 15). Ha T1 közben T2 végrehajtódik, T1 értéke nem az elvárt lesz
- Durability (Tartósság) → tranzakció végén disk-re kiírva van az adat (nem csak memóriában)
Izolációs alapproblémák¶
- sok párhuzamos tranzakció
- izoláció: "úgy kell végrehajtani, mintha egymás után történnének és nem párhuzamosan"
- de párhuzamosan futnak a tranzakciók
- 4 alap probléma:
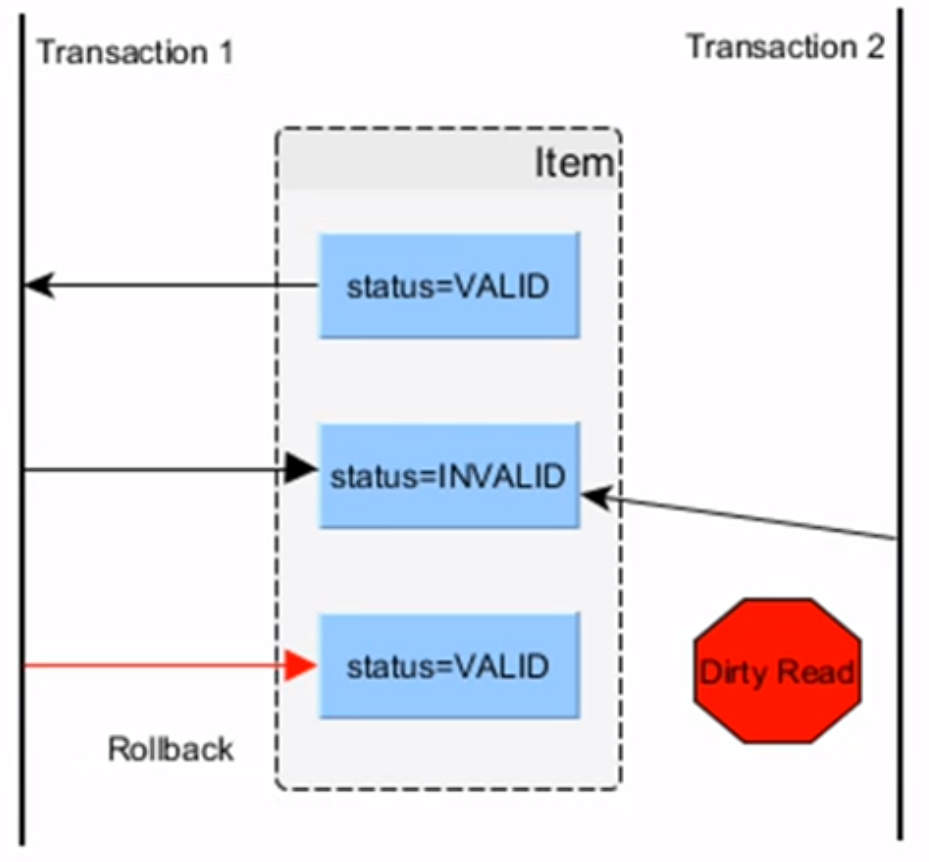
- piszkos olvasás (dirty read) → T1 elkezd futni, de abortál, így T2 egy nem commitált tranzakció által módosított értéket olvasott ki
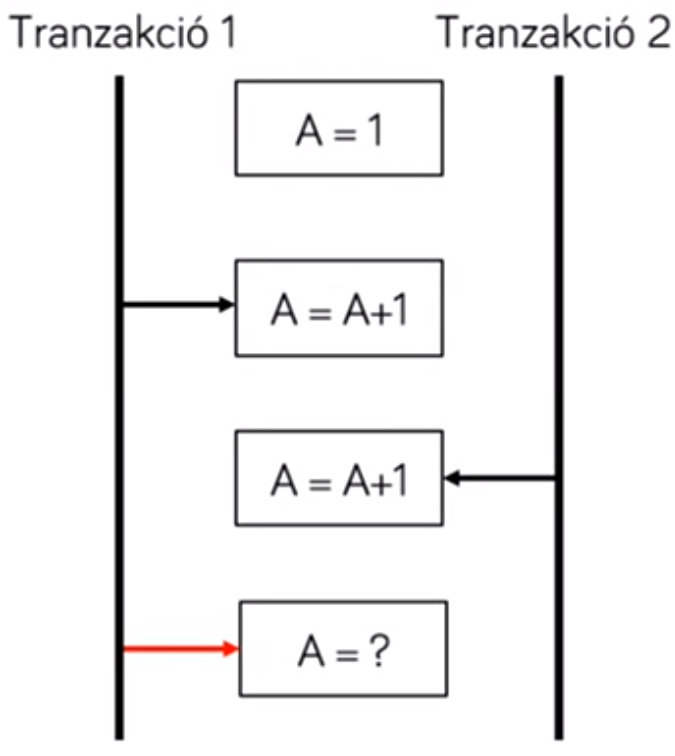
- elveszett módosítás (lost update) → T1 és T2 is módosította, majd T1 olvasná, és nem azt látta amire ő írta át
- nem megismételhető olvasás (non-repeatable read) → időben 2x kiadva ugyanazt a lekérdezést, más eredményt kap T2
- fantom rekordok (phantom read) → rekordhalmazoknál kerül elő: T2 olyan rekordot módosít, ami benne van T1 által épp olvasott rekordhalmazban
- piszkos olvasás (dirty read) → T1 elkezd futni, de abortál, így T2 egy nem commitált tranzakció által módosított értéket olvasott ki
- Fontos: nem csak relációs adatbázisokban, hanem minden többfelhasználós, elosztott rendszerekben megjelenhetnek!
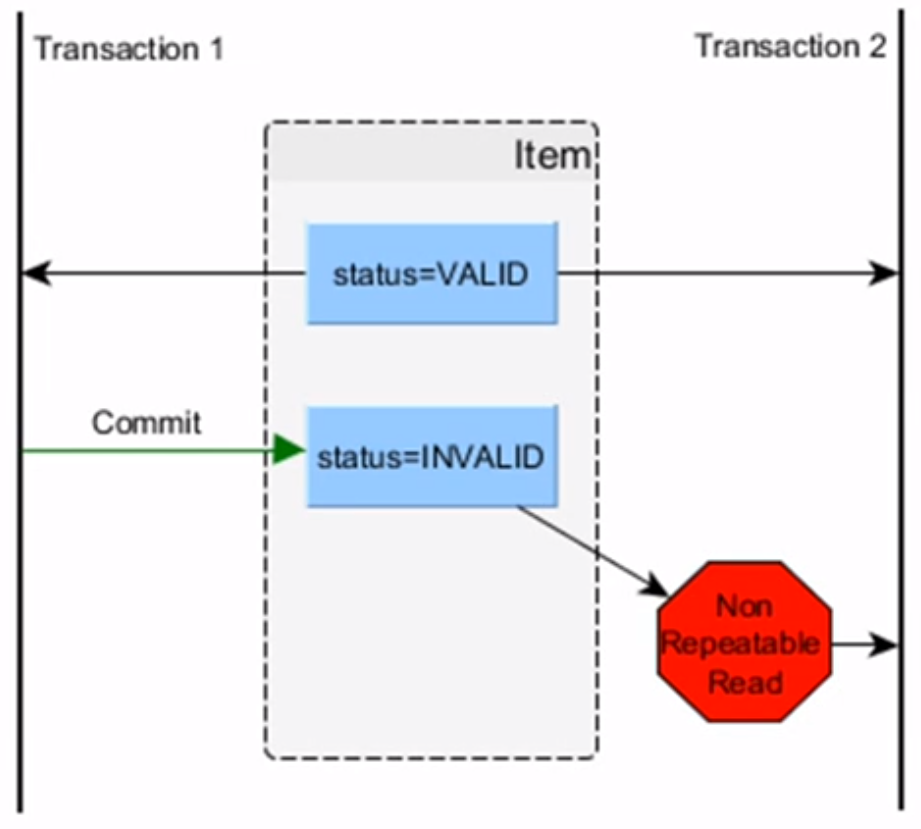
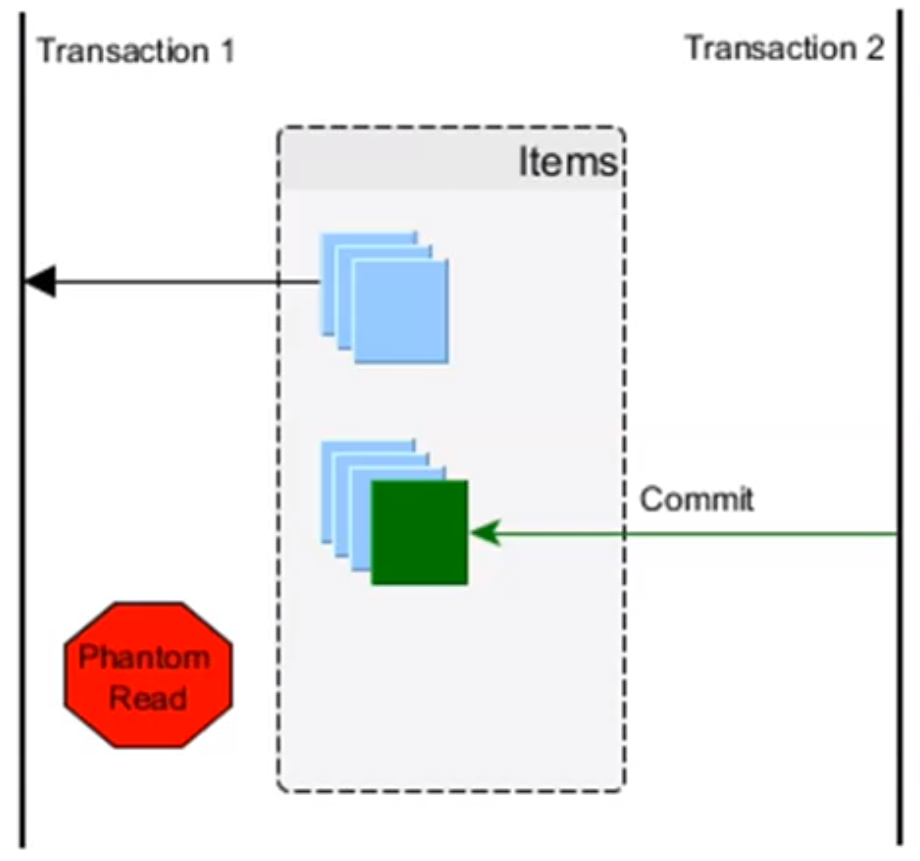
Izolációs szintek SQL szabvány szerint → ezeket a rendszer garantálja, de nekem kell jeleznem!¶
- Read uncommitted → mind a 4 probléma előfordulhat
- Read committed → nincs piszkos olvasás (ez az alap szint)
- Repeatable read → nincs piszkos olvasás, se nem megismételhető olvasás
- Serializable → egyik probléma se fordulhat elő
Tranzakciók ütemezése (megoldás az izolációs alapproblémákra)¶
- Csak olyan műveletek engedhetők meg, melyek nem sértik a helyes ütemezést
- Ha sérülne a helyes ütemezés, akkor a tranzakció vár
- probléma: nem tudjuk előre, hogy melyik tranzakció mit akar csinálni (csak futás közben látjuk)
- Olyan ütemezés megengedett, mely konfliksekvivalens egy soros ütemezéssel
- azaz van egy olyan átrendezése a tranzakcióknak, ahol soros ütemezés teljesül
Ütemezés biztosítása¶
- Kétfázisú zárolás (2PL) → ha egy tranzakció hozzá akar férni egy erőforráshoz, arra zárat rak, majd ha elvégezte a dolgát (commit), leveszi a zárat.
- probléma: holtopont (deadlock)
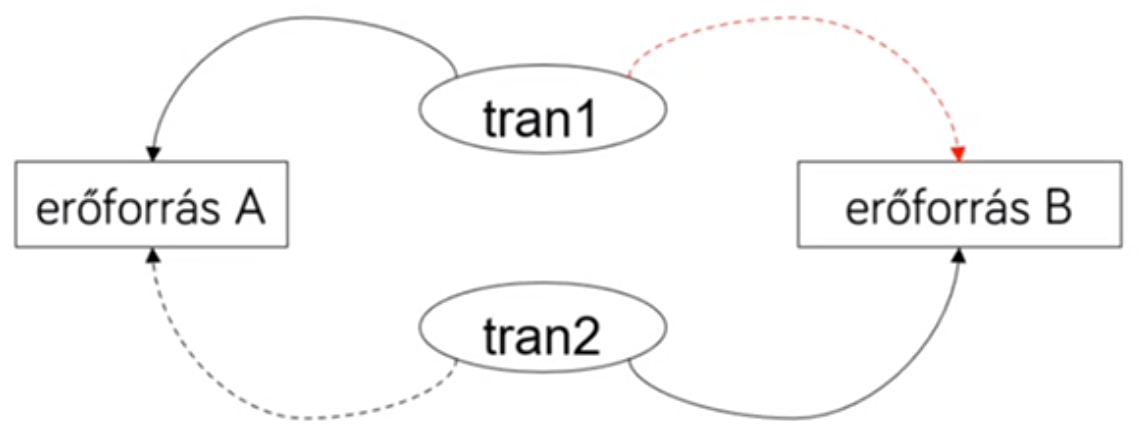
- Ha Serializable-t használunk, akkor gyakran fordul elő holtpont → csökken a hatékonyság
Adatbázis¶
- Def: Logikailag összefüggő adatok rendezett gyűjteménye
- adat → mérhető és rögzíthető, sokféle lehet
- rendezett → könnyű tárolás, módosítás lekérés
- összefüggő → szükséges adatok kellenek
- Metaadat
- adatdefiníció, adatstruktúra, szabályok és korlátozások
- adatszótár (data repositiry / data dictionary)
Relációs adatmodell¶
-
matematikai alap
-
alap komponensek
- tábla vagy reláció, adatok sorokban és oszlopokban
- 2d reprezentáció, megnevezett oszlopok vannak, sorok száma korlátlan
- sor és oszlop kereszteződése → cella, ebben max 1 érték van
- nincs két egyforma sor → nem teljesül a halmaz tulajdonság
- sorok sorrendje lényegtelen
-
integritási kritériumok = érvényességi szabályok (milyen hosszú lehet egy szöveg)
- tartományi integritás → egy adott oszlopban milyen tartományból származó érték lehet (adattípus, hossz, értéktartomány megszabása)
- entitás integritás → 1 rekord mikor érvényes (elsődleges kulcs sehol se lehet NULL)
- referenciális integritás → táblák között, pl külső kulcsok (csak létezőre hivatkozhat, hivatkozott rekord nem törölhető)
- működési korlátozás → üzletvitelből származó, üzleti logika feladata mert relációs modellen túlmutat (pl tárgy csak tárgyfelvételi időben vehető fel)
-
adatmanipulációs nyelv
- relációs algebrából adódóan → SQL
- tábla vagy reláció, adatok sorokban és oszlopokban
-
elnevezések
- attribútum → nevezett oszlop
- rekord → sor
- fokszám → attribútumok száma
- kardinalitás → sorok száma
-
felhasználói séma = objektumok az adatbázisban
- adatbázisban levő objektumok összessége
- platform függő elemek
Microsoft SQL Server platform - MSSQL¶
- stabil adatbázisrendszer
- szerver komponensek → sok van belőlük, komplex rendszer
Felhasználói séma elemei¶
- tábla
- oszlop
- computed column = számított oszlopok
- lehet virtuális (mindig újra számolódik), és tárolt is
- nézetek = lekérdezések eredményei
- indexelhető → ilyenkor tárolódik (amúgy nem tárolódik)
- indexek = megmondja az adatbázisnak, hogy hogyan fogunk benne keresni
- jobb index → gyorsabb keresés az adatbázison
- szekvencia
- számláló
- megadjuk, hogy honnan indul, hányasával lépked, stb
- programmodul
- eljárás, függvény, trigger, assembly
Adattípusok¶
- szöveges adattípusok
- char(n), varchar(n)
- nchar(n), nvarchar(n) → ékezetes karaktereket is tud tárolni (unicode)
- varchar(max), nvarchar(max) → ezt kerüljük
- char és nchar → fix hosszú, többi helyre szóközt tesz
- varchar, nvarchar → változó hosszú
- numerikus
- int, float, numeric(p, s)
- dátumok
- datetime → 1753. január 1-től tud számot reprezentálni
- datetime2 → időzónát is tárol, minvalue-t is tud
- nagyméretű objektumok
- Image, TEXT
- egyéb
- Money, SQL_VARIANT, VARBINARY (ez jobb a nagyméretű objektumoknál), XML
Elsődleges kulcsok generálása¶
-
Identity kulcsszó
create table Statusz( ID int identity(1, 1) primary key, Nev nvarchar(20)) insert into Statusz values ('Kész')-
lekérdezése ennek
- ident_current('Status'), TODO itt is hiányzik még valami
- ha lehet mindig generált elsődleges kulcsot használjunk
- ident_current('Status'), TODO itt is hiányzik még valami
-
Tranzakciós határ¶
- kapcsolat szintjén létezik a tranzakció
- tranzakció kezdés módjai (beállítás függő)
- auto commit → minden utasítás önálló tranzakció (alapértelmezett)
- explicit tranzakciók → explicit tranzakció
begin tran, egymásba is ágyazhatók - implicit tranzakciók → tranzakció vége jel után jön új tranzakció
- DML és DDL utasítások is tranzakciók része
Izolációs szintek támogatottsága¶
- minden SQL szabvány szerinti szintet támogat
- a Read committed az alapértelmezett
- olvasás: megosztott zárakat használ
- írás: más nem olvashatja
- szabványtól eltérő → snapshot
- tranzakció kezdetekor pillanatkép, az olvasható
- adatbázis szinten engedélyezni kell
- jó cucc, de NAGYON drága (külön engedélyezni kell adatbázis szinten)
Adatbázisok tárolása¶
- adatbázis
- adatfájl (.mdf), filegroup is lehet
- tranzakciós napló (.ldf)
- több sémát tartalmazhat
- alapértelmezett séma: dbo
- ez jó logikai csoportosításra, hozzáférés szabályozására
- rendszer adatbázisok: Master, Model, stb
Hozzáférés szabályozás¶
- rendszer szintű → adatbázis szerverhez ki férhet hozzá
- adatbázis szintű → konkrét adatbázishoz
- séma szintű → sémák csoportosítása
- objektum szintű
- konkrét objektumhoz, esetleg objektum szinten is megadható
- tiltás is megadható
- sor szintű hozzáférés nem szabályozható
Tranzakciós naplózás¶
TODO → jegyzetből elolvasni
Adatbázis szerver oldali programozás¶
- Adatmodell: táblák
- Adatmanipuláció: SQL nyelv
- Vannak feladatok, amik kimutatnak a relációs adatmodellből
- Üzleti logikai rétegben valósítjuk meg
- Adatrétegben valósítjuk meg → Adatbázis szerveroldali programozása
- Szerveroldali programozás előnyei
- Adatbázis felelős a konzisztenciáért (innentől már adatforrás és szolgáltatás is)
- Adatbiztonság
- Teljesítmény növelés (csökkenő hálózati forgalom, cache is jobb lesz)
- Termelékenység (egyszerűbb karbantartás, több komponens által hívható modulok készítése)
- Szerveroldali programozás hátrányai
- Nem szabványos dolgok (platformfüggő elemek)
- Interpretált (azaz nem lefordított kód, teljesítménye rosszabb)
- Növeli a szerver terhelését
- Nem illetve nehezen skálázható
Transact-SQL nyelv (T-SQL)¶
-
Csak az MSSQL Server nyelve
-
amik lesznek: változók, utasítás blokkok, ciklusok, strukturált hibakezelés, új konstrukciók
-
utasítás blokk
BEGIN /*TSQL utasítások*/ END -
változók
- DECLARE-el deklaráljuk, @-al kezdődik a nevük
- deklarálás után a változó értéke NULL
DECLARE @nev nvarchar(30), @szam int = 5DECLARE @szam int SET @SZAM = 3DECLARE @szam int, @nev nvarchar(30) SELECT @szam = id, @nev = nev FROM termek WHERE ... /*ha a lekérdezés több sorral tér vissza, a változó értéke az utolsó sor értékével fog megegyezni*/ -
vezérlési szerkezetek
IF ... ELSE WHILE /*ciklusvezérlő utasítások*/ BREAK CONTINUE
Tárolt eljárások¶
- tárolt, mert az adatbázis szerverben van
- eljárás, mert nincs visszatérési értéke
- Belső
- T-SQL nyelv
- interpretált
- zárt környezetben van
- Külső → .NET assembly
Tárolt eljárás létrehozása¶
create or alter procedure- létrehozza/módosítja a tárolt eljárást a sémában
- értelmezi, ellenőrzi, eltárolja
- első futtatáskor → fordítás, optimalizálás
- stored prucedure cache → használaton kívüli tervek elöregednek
Tárolt eljárás újrafordítása¶
- ha releváns tartalom változik az adatbázisban → újra lesz fordítva
- újrafordítás kérése → sp_recomplie
Tárolt függvények¶
- van visszatérési értéke, nem változtathat az adatbázisban (csak olvashat, írni nem írhat)
- Típusai
- Scalar-valued → értéket számol ki (min, max)
- Table-valued → rekordhalmazzal tér vissza
- Aggregate → saját oszlopfüggvény, .NET Assembly-ben írunk ilyet
- van jónéhány beépített (string hossza, string üsszefűzése, stbstb)
Tárolt eljárások kezelése¶
- módosítás →
ALTER PROCEDURE - törlés →
DROP PROCEDURE
Hibakezelés¶
-
@@Error függvény
- minden utasítás után lekérdezhető
- ha nincs hiba, akkor 0-t ad vissza
-
struktúrált kivétel kezelés
BEGIN TRY /*utasítások*/ END TRY BEGIN CATCH /*utasítások*/ END CATCH -
hiba generálás
- Raiserror
- Throw
Triggerek¶
- eseménykezelő tárolt eljárások
- mire használható:
- származtatott értékek karbantartása (denormalizáció)
- naplózás
- statisztikák gyűjtése (hányszor történt meg valami)
- máshogy nem kifejezhető referenciális integritás
- események
- DML események → mikor módosul a tábla, táblához kötődik
- DDL triggerek → create, alter, drop, sémákhoz kötődnek
- rendszeresemény → logon, logoff, syserror, ...
- instead of triggerek → adott utasítás helyett valami más hajtódik végre
- DML triggerek → utasítás szintű
- ha 10 sort módosító utasítás van, akkor egybe kapja a trigger azt a 10-et, egyszer hívódik meg
- adatmódosítás után hajtódik végre
- Módosított rekord elérése
- Napló táblákon keresztül
- napló tábla struktúrája:

- csak a trigger-ben értelmezett
- napló tábla struktúrája:
- Napló táblákon keresztül
- Triggerek egymásra hatása
- Kaszkád triggerek → ami kivált egy következő triggert (32 mélységig)
- Rekurzív triggerek → megengedett, de nagyon hagyjuk
- Ugyan ahhoz az eseményhez több trigger kapcsolása
- lehet, de sorrend nem befolyásolható, nem ismert
- Triggerek és tranzakciók
- szülő tranzakció részét képzi egy trigger
- Instead of triggerek → náluk lehet nem okoz rekurziót, ha belőlük a saját táblájukra hivatkozunk
Kurzor¶
- foreach iterátor
- több rekordot visszaadó lekérdezések feldolgozására
Relációs adatbázisok adatszótára¶
-
IF EXISTD→ ha létezik...drop table Invoice→ Invoice tábla eldobása... majd create table -
idempontens script → adatbázis állapotától függetlenül újra lefuttatható és ugyanazt az eredményt adja
-
adatszótár
- központi helyen tárolt információ az adatról, a formátumról, kapcsolatokról → táblák nevei, oszlopok nevei, típusai
- adatbáziskezelő integrált része (de lehet dokumentum is)
- csak olvasható nézet
- felhasználható DML és DDL utasításokban
- adatszótár tartalma
- minden séma objektum leírása (táblák, nézetek, indexek, ...)
- integritási kritériumok
- felhasználók, jogosultságok
- monitoring információk → pl deadlock megtalálására
- auditing információk → ki módosított egyes séma objektumokat
-
MS SQL adatszótár
-
Information Schema Views (ISO standard, pl táblák, nézetek, oszlopok, paraméterek, ...)
-
Catalog Views → teljes körű információ a szerverről
-
Dynamic Management Views → szerver diagnosztikai információk
-
pl:
select * from sys.objectsIF EXISTS ( SELECT * FROM sys.objects WHERE type = 'U' AND name = 'Product') DROP TABLE Product
-
Félig strukturált adatok kezelése¶
XML¶
-
adatbázis és txt fájl között vannak kb
-
XML: Extensible Markup Language
- adatok szöveges, platformfüggetlen reprezentációja
- emberileg és géppel is jól olvasható
- célja: egyszerű, általános használat
- eredetileg dokumentum leírásnak készült (pl OpenXML, XHTML)
- önleíró
- sémát és adattartalmat is egyben tárol
-
felépülése
<?xml version="1.0" XML deklaráció encoding="UTD-8"?> <!-- komment --> <elem attributum="érték"> <tag>tartalom</tag> <![CDATA[ bármilyen tartalom ]]> </elem> -
XML hátrányok
- szöveges adat reprezentáció
- platformon belüli használt sorosítás → nem gond
- szabványra épülő megoldás (pl. SOAP)
- dokumentált séma (pl. XSD)
- nem definiált adattípusok → dátum, bool (true vagy 1?)
- nem egyértelmű adatreprezentáció → null (üres reprezentáció, vagy oda se írom a kacsacsőröket? üres string vs null?)
- szöveges → nagyobb méret
- szöveges adat reprezentáció
-
XML .NET-ből
-
System.Xml.Serialization.XmlSerializer
[XmlElement("Cim")] public class Address { [XmlAttribute("Varos")] public string city; }
-
-
séma
- XML dokumentum jól formázott
- minden nyitó tag le is van zárva, zárójelezés szabályai szerint
- egyetlen gyökér eleme van
- tartalom érvényessége bonyolultabb
- jó névvel vannak benne a tagek? helyes bennük a tartalom?
- DTD vagy XSD való ennek leírására
- validálás: egy adott XML dokumentum megfelel-e egy adott sémának → programozottan eldönthető
- XML dokumentum jól formázott
-
DOM: Document Object Model
-
XPath
konyvtar/konyv→ relatív címzés/konyvtar/konyv→ abszolút, azaz a gyökérhez képest//konyv→ hierarchiához képest bárhol lefele//@nyelv→ bárhol egy nyelv nevű attribútum/konyvtar/konyv[1]→ első talált elem (1-től indexelünk)/konyvtar/konyv[ar>5000]→ adott tulajdonságú megkeresése
JSON¶
- JavaScript Object Notation, de nem csak javascript
- tulajdonságai:
- kompakt, olvasható, szöveges reprezentáció
- előny: kisebb méret (nincsenek felesleges záró tag-ek)
- memóriabeli objektum = egy JSON objektum
- alapelemei:
- objektum → kulcs-érték párok halmaza
- tömb → értékek halmaza
- érték → szöveg, szám, igaz/hamis, null, objektum, tömb (van null és bool :) )
- ami NINCS benne:
- nincs komment
- nincs egyértelmű reprezentáció → pl dátum még mindig nincs! :(
- biztonsági kockázat → JSON eredményt JavaScript motorral végrehajthatunk (
eval())
- mikor használjuk?
- backend → vékonykliens kommunikáció
- tömör, rövid (kevés hálózati forgalom, mobil klienseknek előnyös)
- javascript tudja parsolni (webes rendszerekben)
- REST
- JSON relációs adatbázis
- MS SQL Server 2016, MongoDB
- backend → vékonykliens kommunikáció
- JSON .NET-ben
- OpenSource → JsonConvert.DeserializeObject...
XML vs JSON¶
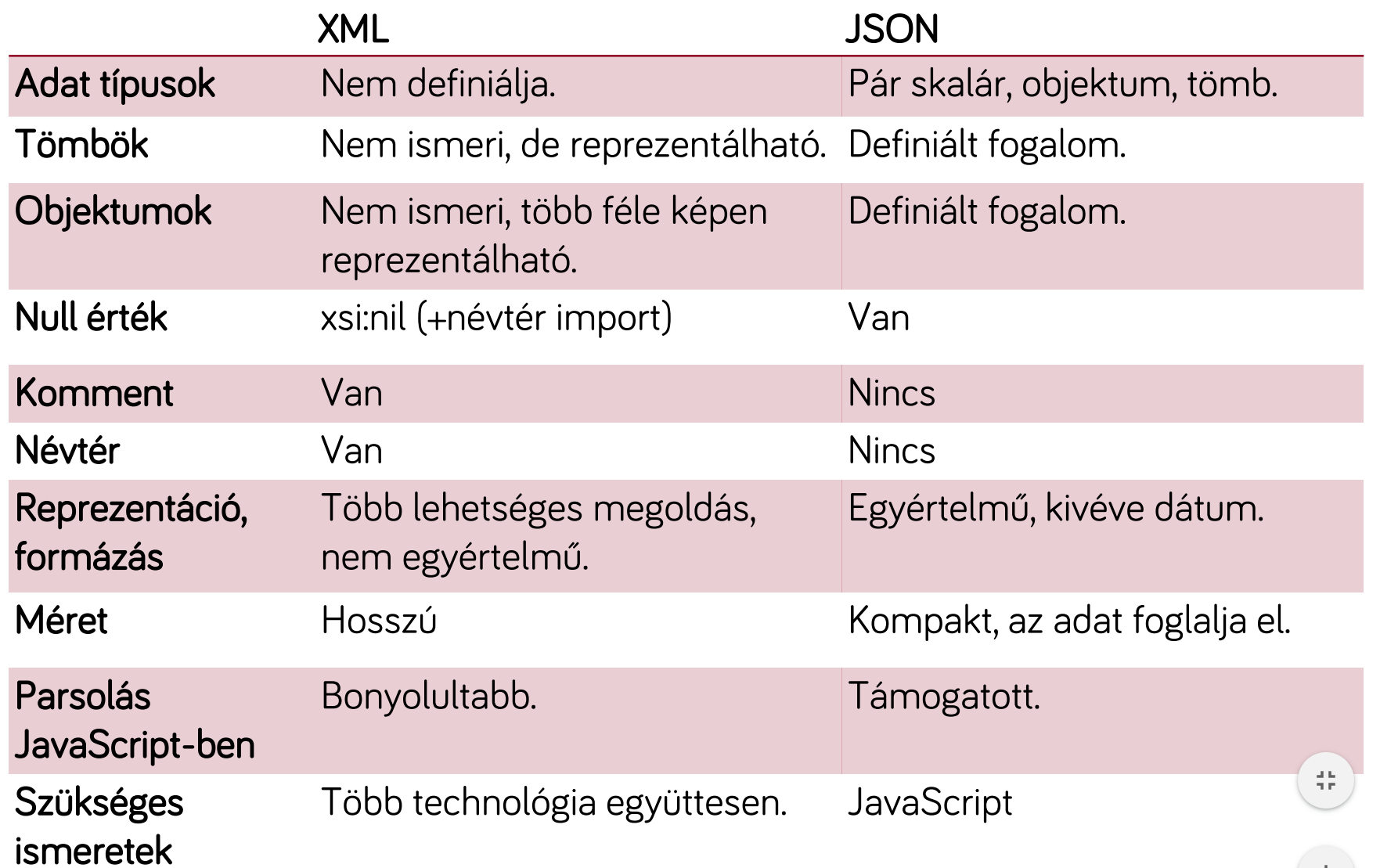
XML kezelés relációs adatbázisokban¶
-
mikor?
- létező XML formátumú adatok
- ismeretlen, nem definiált formájú adat
- külső rendszerből ilyen formában érkeznek, vagy külső rendszernek ilyen formában kell átadni
- csak tárolt, nem manipulált adattartalom
- mélyen egymásba ágyazott adatformátum (nagyon sok tábla és join kellene a reprezentálásához)
-
XML-képes relációs adatbázisok → pl MS SQL, Oracle, ...
-
relációs adatok mellett xml adatok is
- relációs a fő tartalom!
-
XML adat köthető relációhoz → termék adatai az ár és név mellett egy XML leírás
-
tárolás módja:
- nvarchar(max) → validáció nélküli szöveg, futás időben konvertálható (költséges)
- xml → jólformázottnak kell lennie, kereshető lesz a tartalom (where-be is használható), indexelni is lehet, csatolható hozzá séma ami ellenőrzi, manipulálható (törölhető egy tag)
-
2 fajta index
- elsődleges → teljes tartalmat indexeli
- egy ilyen definiálható
- másodlagos → konkrét xml elemekre definiált
- elsődleges → teljes tartalmat indexeli
-
séma hozzárendelés xml oszlophoz (opcionális)
- adat validáció automatikusan
- lekérdezés optimalizáláshoz is
-
xml-ben keresés → XPath-al
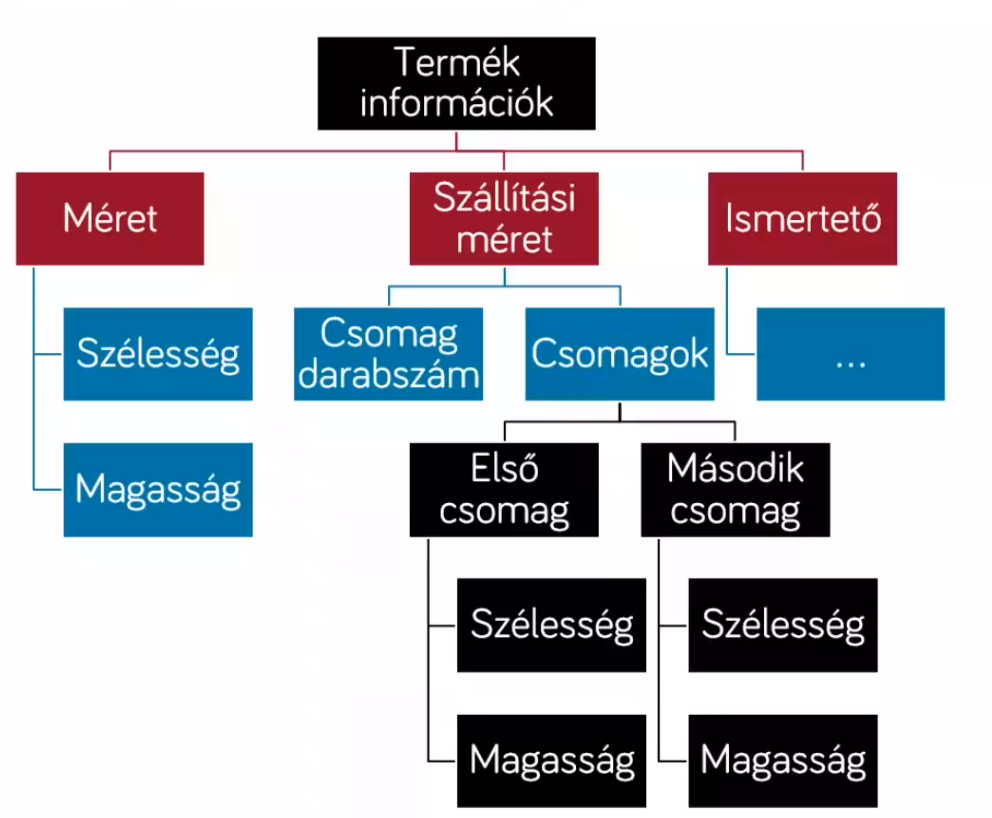
/* példa1 - projekció */ select Description.query('/product/num_of_packages') from Product /* példa2 - konkrét érték kiszedése */ select Description.value('(/product/num_of_packages)[1]', 'int') from Product /* példa3 - szűrési feltétel */ select Name from Product where Description.exist('/product/num_of_packages eq 2') = 1 /* példa4 - módosítás replace */ update Product set Description.modify('replace value of (/product/num_of_package/text())[1] with "2"') where ID=8 /* példa5 - módosítás insert */ update Product set Description.modify('insert <a>1</a> after (/product)[1]') where ID=8 /* példa6 - módosítás törlés */ update Product set Description.modify('delete /product/a') where ID=8 -
lekérdezés eredményét XML-ben lekérése → for xml auto
select ID, Name for Customer for xml auto
LINQ¶
-
motiváció - C#
- kinek van ma szülinapja? → for mindenki, ha ma van szülinapja adja
birthDayTodaylistához - ez SQL-lel SOKKAL könnyebb lenne! → dekleratívan könnyebb megadni (mint imperatívan = hogyan)
- kinek van ma szülinapja? → for mindenki, ha ma van szülinapja adja
-
speciális gyűjteményekkel megy →
IQueryable,IEnumarable -
lambda kifejezése
bool foo(int value) { return value % 2 == 1; } value => value % 2 == 1; //lambda kifejezés- általánosan:
(in1, in2) => { code; return something; }
- általánosan:
-
LINQ szintaktika
-
szintaktika:
from m in list where m.Title.StartsWith("S") select m.Title; -
szebb szintaktika:
list .Where( m => m.Title.StartsWith("S")) .Select( m => m.Title);
-
-
LINQ to *
- Linq to Objects → minden gyűjteményen használható
- Linq to Entity Framework → SQL kóddá fordul
- Késleltetett kiértékelés → eredményhalmaz iterálásakor keletkezik (mikor a leírón végig megyünk)
- addig csak leíróként van meg!
- System.Linq névtér
Adatelérési réteg¶
- adatelérési réteg feladata
- adatelérési absztrakció biztosítása (ne kelljen foglalkozni a konkrét adatbázis implementációval)
- konkurenciakezelés
Repository¶
-
adatforrás (adatbázis) és üzleti logika közt van
-
adatelérési rétegben vannak repozitory-k
-
entitásokkal doglozik (entitás = osztály, ami reprezentál egy terméket)
-
repozitory
- entitásonként vagy entitás csoportonként (pl termék és kategória)
- technikailag egy osztály, interfésszel absztraháljuk el
- 2 fajta művelet → CRUD (Create Retread Update Delete) műveletek, és egyéb bonyolultabb műveletek
- üzleti entitásokkal dolgozik (nem azzal ami az adatbázisban van)
- minden technológia-specifikus rész itt van bezárva → technológia és platform függő
-
példa:
class ProductRepository : IProductRepo { //CRUD műveletek: List<Product> List() { ... } Product FindById(int Id) { ... } void Add(Product entity) { ... } void Delete(Product entity) { ... } void Update(Product entity) { ... } //bonyolultabb műveletek: void AddProductToCategory (Product p, Category c) { ... } void StopSellingProduct(Product p) { ... } }
konkurenciakezelés¶
- itt nem mindig működnek az izolációs szintek (nem nagyon létezik a tranzakció fogalma itt)
- backend-hez közel még működhet, frontend-ből vissza már nem
- 2 fajta megoldás:
- pesszimista konkurencia kezelés
- feltételezzük, hogy problémánk lenne ebből a módosításból → kizárólagosság biztosítása az adathoz
- optimista
- többség úgyis csak olvas, írás miatt ritkán lenne ütközés, ha mégis akkor detektáljuk
- pesszimista konkurencia kezelés
Pesszimista konkurencia kezelés¶
- meg akarja akadályozni a konkurens módosításokat
- erre jók a tranzakciók, ha kapcsolatunk van az adatbázissal (csak rövid időre tarthatóak fel)
- üzleti logikában nyilvántartjuk az éppen módosító folyamatokat, a többit gátoljuk
- ezt nehéz jól csinálni, de lehet
- sorbarakjuk a módosításokat
Optimista konkurencia kezelés¶
- nézzük, hogy volt a probléma
- változások adatbázisba való visszaírásáig el tudunk menni
- probléma: valaki átírta az adatot
- rekord tartalom alapján döntünk
- rekord verzió (számláló vagy időbélyeg)
- teljes tartalomvizsgálat (módosítás előtti megegyezik e a mostanival)
- nehézség: meg kell őrizni a módosítás előtti tartalmat
- hátrány: implementálni kell az olvasós és mentős sql utasításokban!
ORM¶
- objektum-relációs leképzés
- feladat: üzleti logika és adatbázis közti leképzés
- üzleti logikában → OO modellezés, UML, design patterns, statikus adatt mellett folyamatok is vnanak
- adatréteg → E/K diagram, UML data modelling, csak statikus adatok
- leképzés → ORM = objektum-relációs leképzés
- problémák: eltérő koncepciók, öröklődés, shadow információk, kapcsolatok leképzése
Alapkoncepció¶
- osztály = tábla
- adattagok = tábla oszlopai
- kapcsolat = külső kulcs
Problémák¶
- összetett mezők → vásárló = cím(irányítószám, város, utca)
- megoldás1: vásárlóban implementáljuk az irányítószám, város és utca attribútumot
- megoldás2: külön táblát csinálunk cím néven, és külső kulccsal kötjük őket össze
- eltérő adattípusok
- dátumok nehezek
- string =? nvarchar(???)
- korlátokat kell kezelni!
- shadow információk
- pl id-k, időbélyegek (c#-ban a referencia azonosítja az adatot, üzleti logikába kb felesleges DE mégis kell)
- SOLID elvet sértünk vele! (több felelősségük lesz)
öröklés megvalósítása¶
- Probléma:
- Person → absztrakt osztály
- több implementációja van
- új funkció beépítése → új leszármazott keletkezik
- hierarchia leképzése egy közös táblába
- összes attribútum felsorolása a hierarchiát bejárvat
- típus → egy oszlopban kódolt érték, vagy IsCustomer, IsEmpolyee → diszkriminátor oszlop
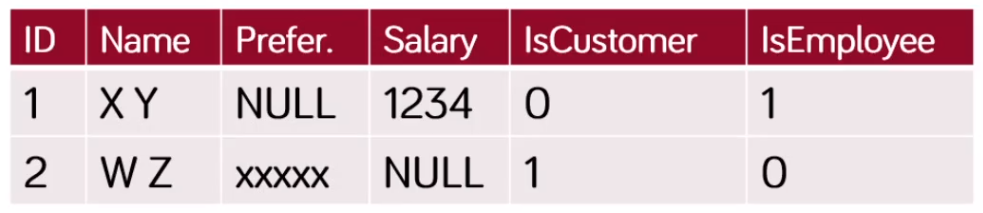
- előnyök:
- egyszerű, könnyű új osztályt bevenni
- objektum példány szerepének változása könnyen követhető (employee-ből executive lesz, vagy employee és customer egyszerre)
- hátrányok:
- helypazarlás, egy osztály változása miatt az összes tárolása megváltozik
- komplex struktúra esetén nehezen áttekinthető
- célszerű: egyszerű hierarchiák esetén
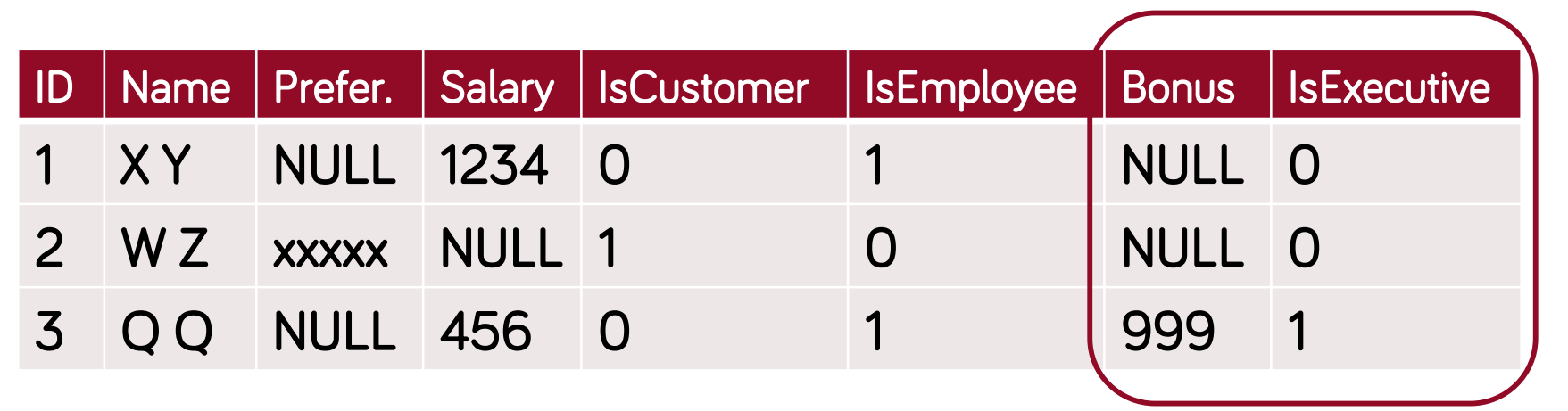
- valós osztályok leképzése saját táblába (akikből objektum példányok képződhetnek)
- osztályonként 1 tábla, abba az összes attribútum és ősöktől örökölt attribútumok eltárolása
- példányazonosító
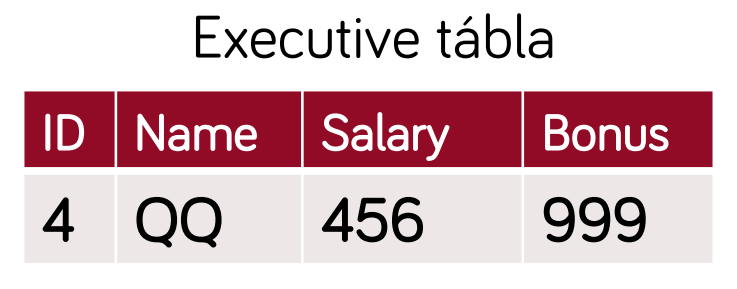
- előnyök:
- átláthatóbb, jobban illeszkedik az objektum modellhez, gyors az adatelérés
- hátrányok:
- egy osztály módosítása több táblát is érinthet, több szerepet betöltő vagy szerepet váltó példányok kezelése nehézkes
- célszerű: ritkán változó struktúrák esetén
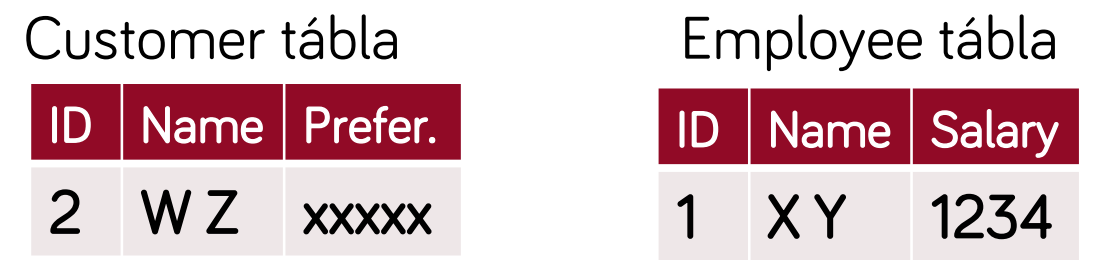
- minden osztály leképzése saját táblába (absztrakt osztályok is)
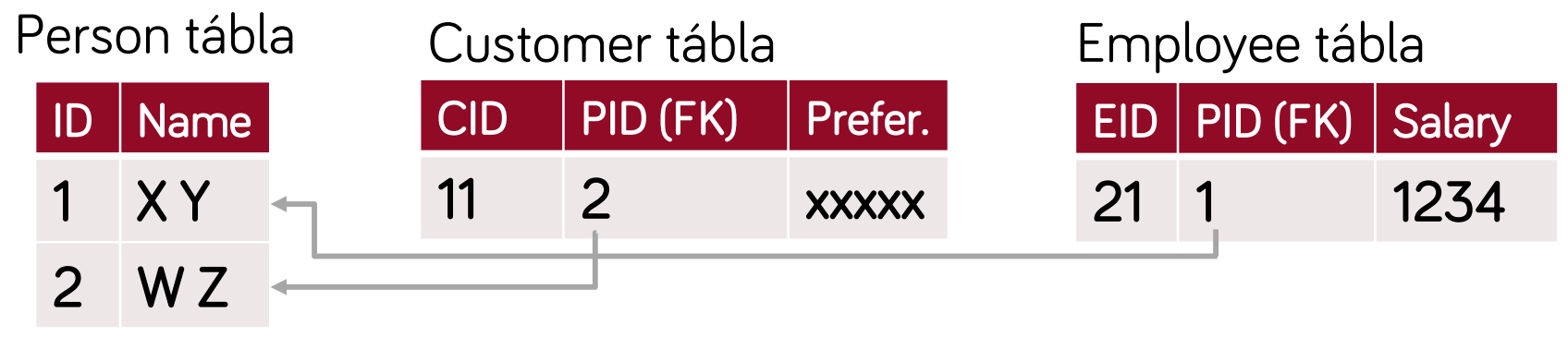
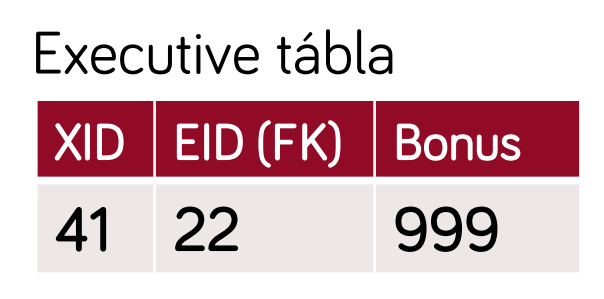
- előnyök:
- könnyű megérteni, könnyű módosítani a szülő osztályok struktúráját (customer-ben változtatás nem érint senki mást)
- hátrányok:
- összetett adatbázis séma = komplexebb
- egy példány adatai több táblában vannak → összetett lekérdezések, join-ok kellenek → lassabb
- célszerű: komplex hierarchia esetén, változó struktúra esetén
- osztályok és hierarchia szintek általános leképzése
- meta data driven megoldás
- általános séma
- tetszőleges hierarchai leírható, független a konkrét osztályoktól
- osztály hierarchai → meta adat
- osztály példányok → attribútumok manifesztálódása
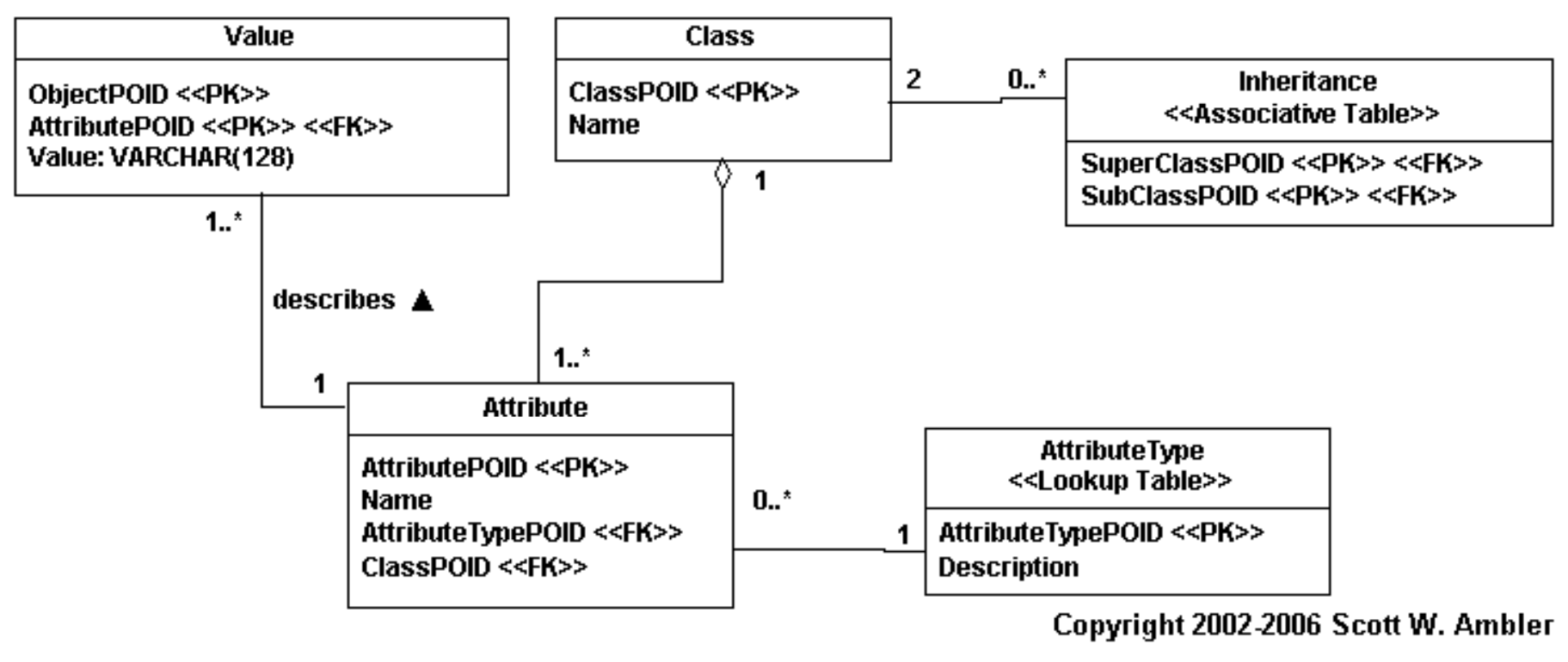
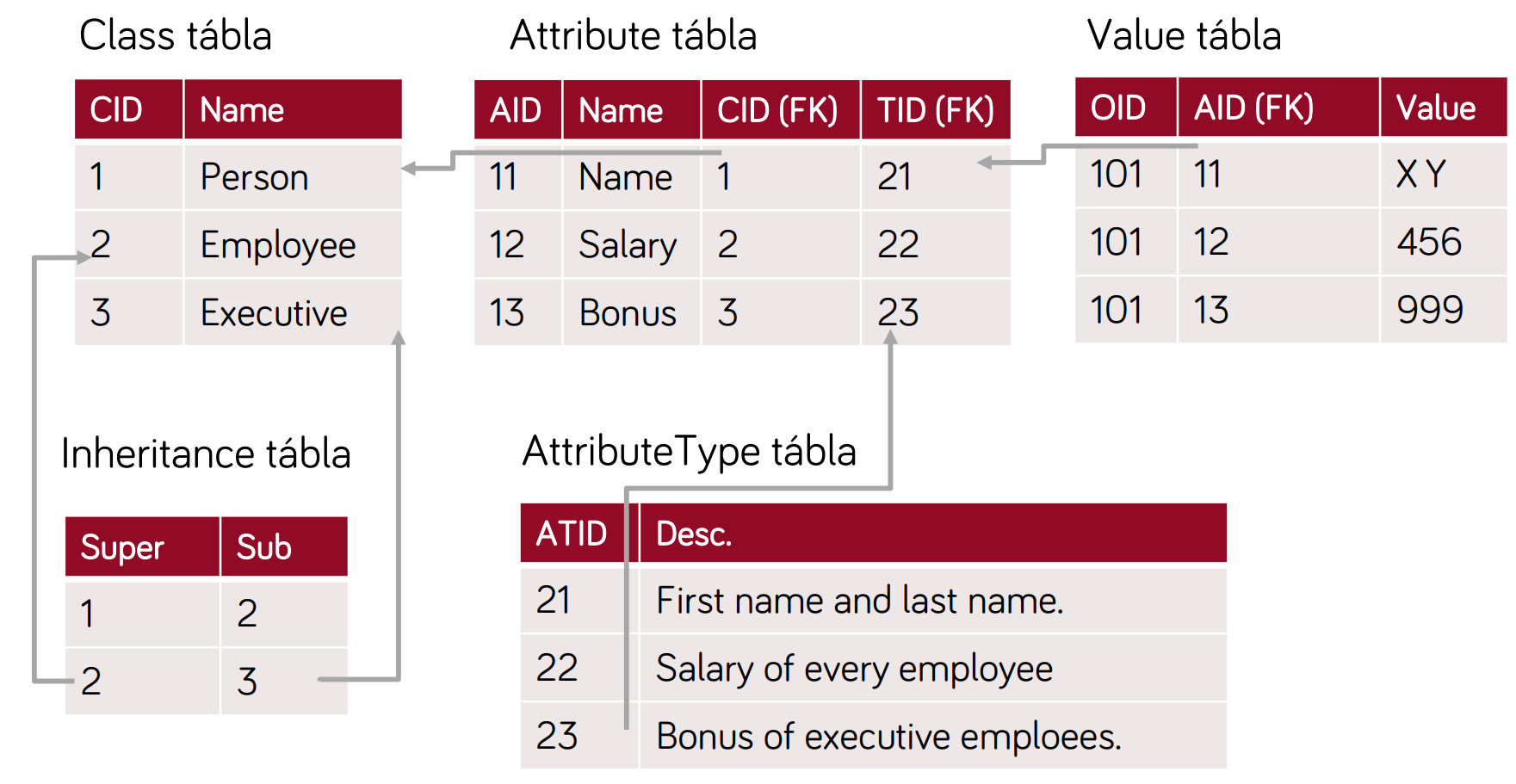
- minden érték a Value táblában van, az attribútum típus és osztály id-k külön helyeken vannak!
- előnyök:
- flexibilis → bármi leírható benne, sose kell új osztály!
- hátrányok:
- picit nehezen megérhető
- nehéz az egy osztályhoz tartozó adatok megtalálása
- nagy adatmennyiség esetén nem hatékony
- célszerű:
- komplex alkalmazásoknál (nemis tudjuk előre, hogy mit akarunk csinálni)
- kis mennyiségű adatok
- minden változhat futási időre (kívülről jönnek az adatok)
többszörös öröklés¶
- C++ miatt még mindig kell vele foglalkozni → eddig nézett módszerek ezt is meg tudják oldani :)
Objektum kapcsolatok leképzése¶
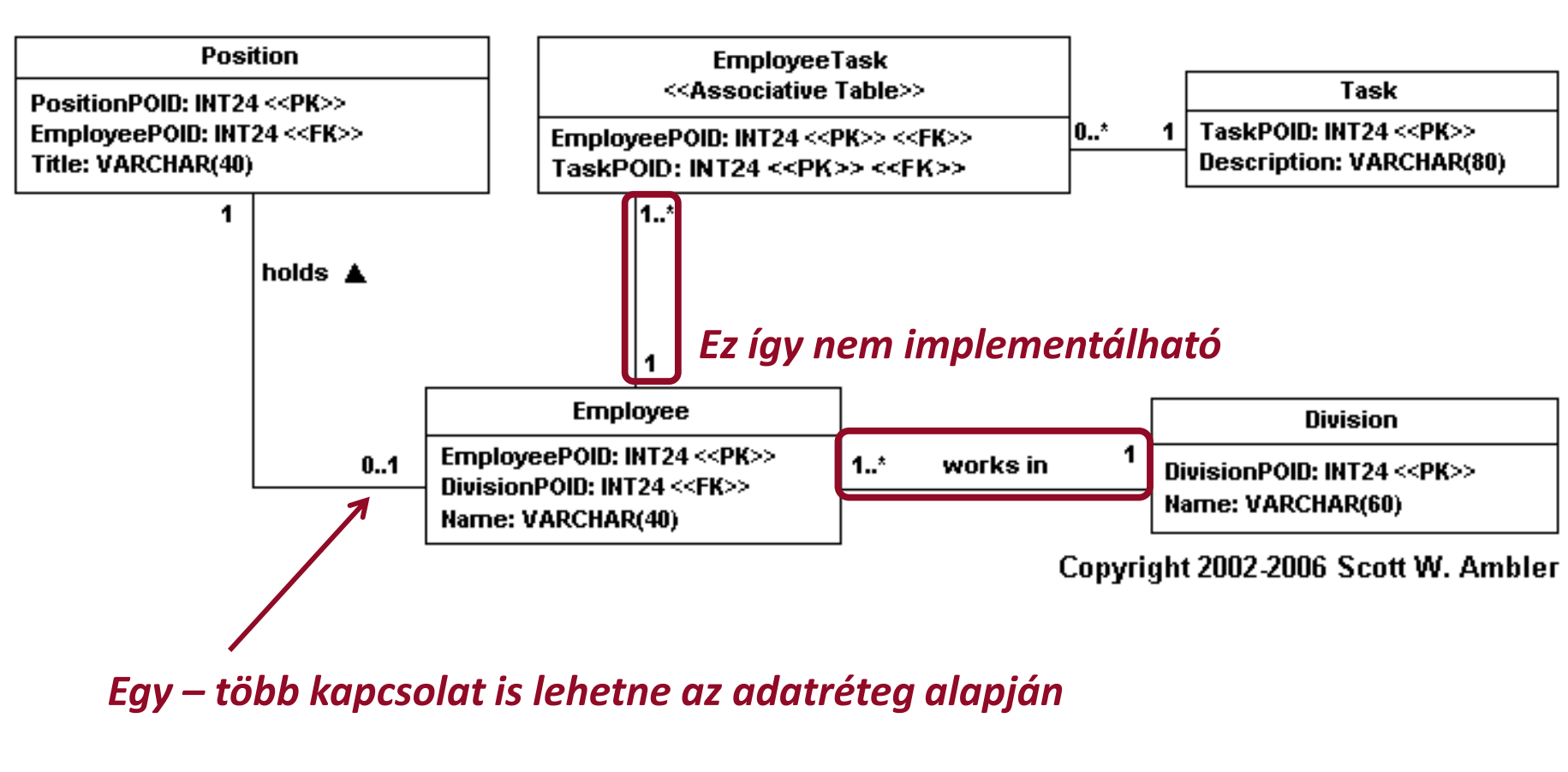
- kapcsolatok: asszociáció, aggregáció, kompozíció → referenciális integritás
- típusai: egy-egy, egy-több, több-több → referenciális integritás
- iránya: egyirányú, többirányú → NEM képezhető le :(
- egy-egy kapcsolat
- külső kulcs az egyik táblára (ettől még egy-több is lehetne)
- egy-több kapcsolat
- külső kulcs az "egy"-re
- több-több kapcsolat
- kapcsoló tábla használatával (két egy-egy kapcsolat)
- kardinalitás → nehezen leírható (nem kényszeríthető, hogy "rám" legyen hivatkozás!)
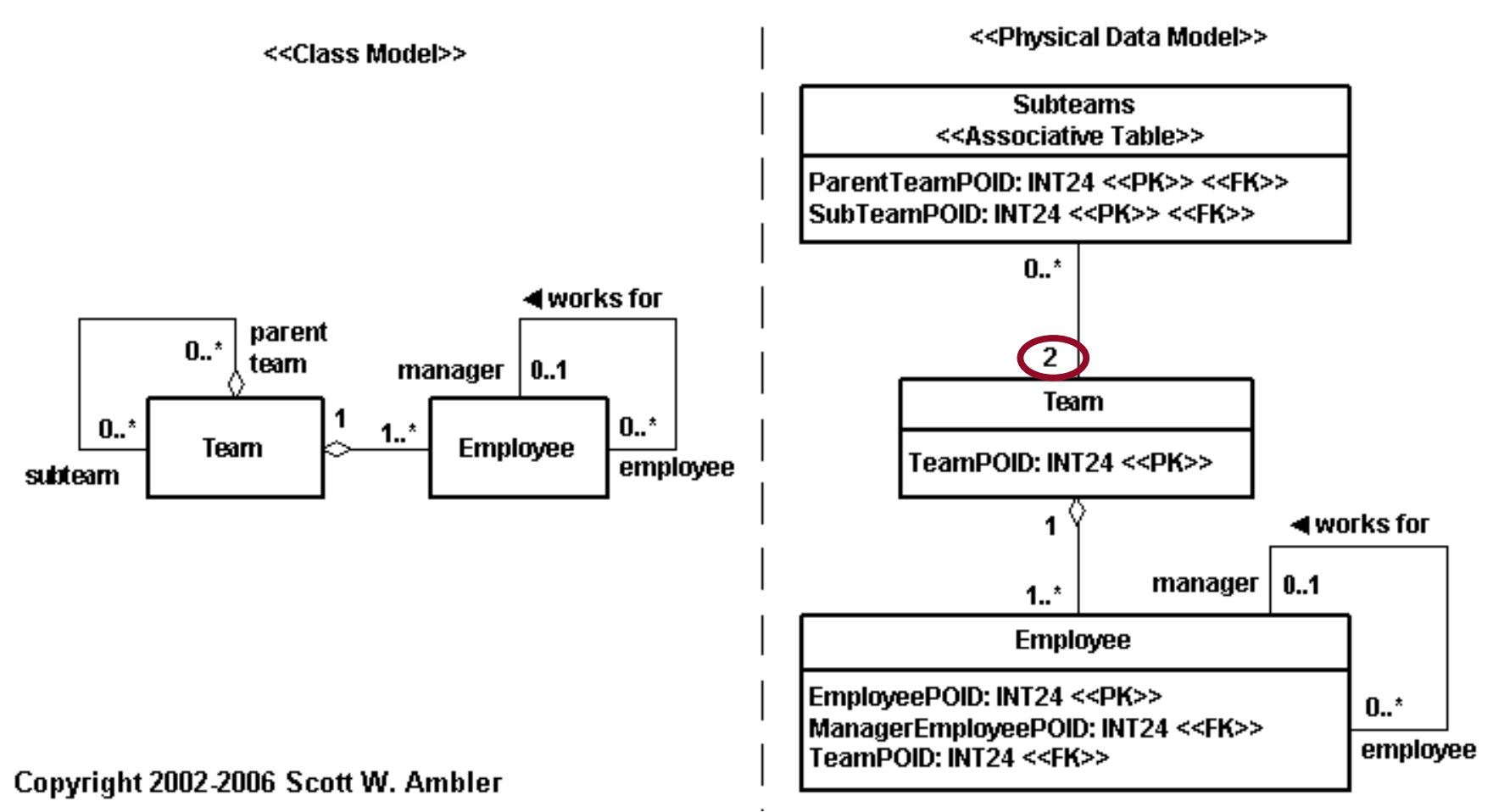
rekurzió (reflekxió)¶
- azaz önmagára mutató kapcsolat
rendezett gyűjtemények¶
- fontos: táblában NINCS sorrend, ezért külön attribútum kell nekünk (SequenceId)
- ez is shadow információ
- sorrendváltoztatás → több változik egyszerre!
- erre egy alternatív megoldás a hézagos felosztás (10-esével adom a sequenceid-ket)
osztály szintű tulajdonságok¶
- statikus adattagok → nem kötődnek példányhoz
- következő számla sorszáma
- kedvezmény értéke bizonyos összeghatár felett
- minden tulajdonságnak külön tábla
- gyors, sok kis tábla → bonyolít
- minden tulajdonság egy táblába
- elnevezése hülyeség lesz (global)
- gyors, egyszerű, DE állandó konkurenciaprobléma lesz
- NEM praktikus
- osztályonkéknt egy tábla az értékek különböző oszlopokba
- gyors, sok kis tábla → bonyolult
- általános megoldás
- egy táblába, sor szinten → minden tulajdonság új rekord (osztály, tulajdonság név, érték)
- adatkonverziót meg kell oldani :(
- egyszerű bővíteni → új tulajdonság = új rekord
ADO.NET¶
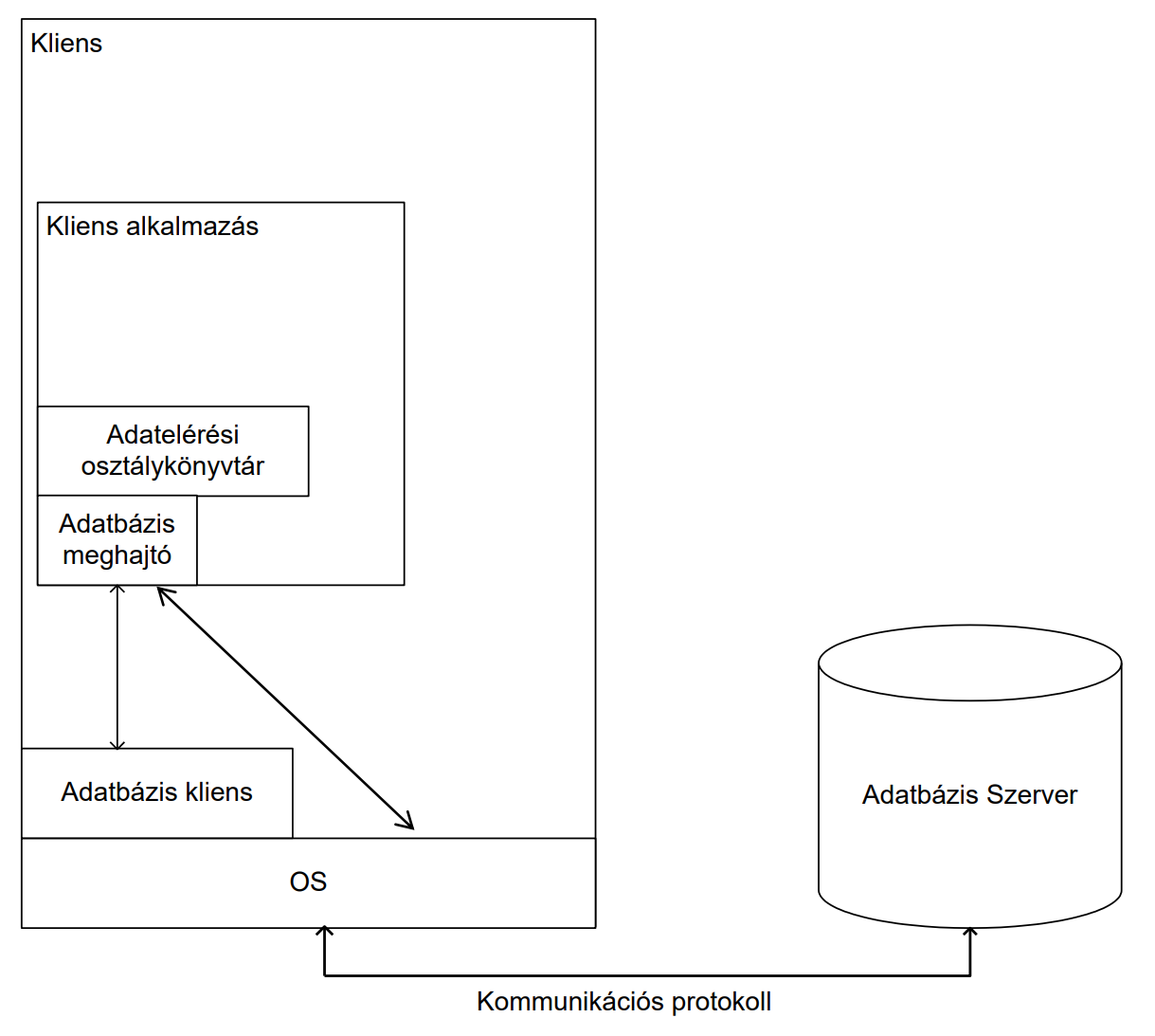
-
adatelérési könyvtár
- adatbázis használat absztrakció (adatbázis elérése, egységes adatbázisfüggetlen kódolás)
- elemei: Connection, Command, ResultSet, Exception
-
adatelérési könyvtár .NET-hez
- interfészeken, absztrakt osztályokon keresztül tudunk így az adatbázissal kommunikálni
- konkrét implementációk Oracle, MySQL, stb szerverekhez
Kapcsolat felépítése¶
-
IDbConnection interfész
- Open, Close, BeginTransaction
-
nyitás és zárás költséges folyamat
-
Connection pooling → cach-elt kapcsolatok (újra felhasználhatóak)
- Connection leak → nehezen kinyomozható
-
Connection String
-
DB szervertől függ a szintaktika
-
sokféle paramétert kell megadni
-
connectionstrings.com
-
Connection string alapú támadások → ConnectionStringBuilder-t használunk!
var builder = new SqlConnectionStringBuilder(); builder.UserID = "User"; builder.Password = "Pw"; builder.DataSpurce = "database.server.hu"; /*builder...*/ var con = new SqlConnection(builder.ConnectionString); con.Open(); //... con.Close();- külön Connection-ok vannak
SqlConnectionaz MSSQL-hez való Connection
- külön Connection-ok vannak
-
-
IDbCommand interfész
- 3 különböző típus (CommandType)
- Tárolt eljárás, Tábla teljes tartalma, SQL query
- parancs szövege (CommandText)
- adatbázis kapcsolat (Connection)
- tranzakció (Transaction)
- timeout (CommandTimeout) → alapértelmezett 30sec
- paraméterek → SQL injection-ra figyelni kell!
- szószerint nem szabad a felhasználótól kapott string-et futtatini SQL parancsként
- 3 különböző típus (CommandType)
-
Parancs végrehajtása
- ExecuteReader: több rekord lekérése
- ExecuteScalar: skalár érték lekérése
- ExecuteNonQuery: eredményhalmaz nélküli parancs (pl: INSERT), érintett sorok számával tér vissza
- ExecuteXmlReader: XML-ként olvassa ki az adatot
- Command.Prepare() → többször egymás után futtatott parancsnál hasznos, szerver oldalon előkészíti a futást
Tranzakciók használata¶
- BeginTransaction: tranzakció létrehozása, izolációs szint itt adható meg
- Transaction tulajdonság: parancs tranzakcióhoz rendelése
- CommitTransaction, RollbackTransaction: tranzakció befejezése
- van általános .NET tranzakciókezelés is (TransactionScope)
- egy tranzakció → max 10perc (és ez NEM megváltoztatható)
- 1 tranzakció 1 connection-höz tartozhat! (különben MSDTC-s hibaüzenet)
- null érték → DBNull.Value, nem pedig a c#-os null (ADO.NET-nél)
Hibakezelés¶
- try-finally block, vagy using (dispose tervezési minta) használata kell!
- reader-t és a kapcsolatot le kell zárni!
DataReader vagy DataSet¶
-
DataReader, azaz kapcsolat alapú modell
-
feldolgozás lépései: kapcsolat megnyitása, parancs futtatása, eredmény feldolgozása, reader lezárása, kapcsolat lezárása
-
általában ezt használjuk, főleg szerveroldalinál
-
kód:
using (var conn=new SqlConnection(connectionString)) { var command = new SqlCommand("SELECT ID, NAME FROM Product", conn); connection.Open(); using(var reader = command.ExecuteReader()) { while (reader.Read()) { Console.WriteLine("{0}\t{1}", reader["ID"], reader["Name"]); } } } -
visszatérni object tér vissza (nem típusos)
-
mikor használjuk?
- pl mikor rövid idejű és folyamatos adatbázis kapcsolat kell a szerverrel, pl webalkalmazások
-
előnyök: egyszerűbb konkurencia kezelés, mindenhol a legfrissebbek az adatok, kisebb memória igény
-
hátrányok: folyamatos hálózati kapcsolat, rossz skálázhatóság
-
-
DataSet, azaz kapcsolat néküli modell
-
feldolgozás lépései: a kapcsolat megnyitása, a DataSet feltöltése, a kapcsolat lezárása, a DataSet feldolgozása, a kapcsolat megnyitása, változtatások visszatöltése, kapcsolat lezárása
-
használat: memóriában módosítgatom csak a dolgokat, majd egyben írom vissza
-
kód:
var dataSet = new DataSet(); var adapter = new SqlDataAdapter(); using (var conn = new SqlConnection(connectionString)) { adapter.SelectCommand = new SqlCommand ("SELECT * FROM Product", conn); connection.Open(); adapter.Fill(dataSet); } //--------------------------------------------------------- foreach(var row in dataSet.Tables[„Product"].Rows) Console.WriteLine("{0}\t{1}", row["ID"], row["Name"]); //--------------------------------------------------------- using (var conn= new SqlConnection(connectionString)){ connection.Open(); adapter.Update(dataSet); // dataSet.AcceptChanges(); // csak az adapter táblája frissül, nem kerül adatbázisba } -
mikor használjuk?
- pl mikor a kapcsolatot csak az adatmanipuláció idejére akarjuk fentartani pl vastag kliens
-
előnyök: nem szükséges folyamatos hálózati kapcsolat, jó skálázhatóság
-
hátrányok: az adatok nem mindig a legfrissebbek, ütközés lehetséges, kliens memóriát foglal
-
Entity Framework¶
-
magasabb absztrakciós szint
-
alapprobléma
- adat és objektum nem egyenlőek → ORM
- SQL → adatorientált és egyszerű lekérdezéseket megfogalmazni
- DE nem típusos, nem objektum alapú, nem épül be nyelvi elemként (String lesz)
- ADO.NET → hatékony, DE nem típusos
-
adatelérés LINQ segítségével
-
példa
from product in db.Products where product.Name == "Lego" select product; -
előnyök: típusos lesz, objektumokra épül, típusellenőrzés fordítási időben
-
-
Entity Framework (EF)
- ORM rendszer
- lehetővé teszi logikai (adatbázis) és fogalmi (üzleti logika) modellek szétválasztását
- függetleníti az adatbázisunkat az adatbázismotortól
-
EDM
-
Entity Data Model
- absztrakciós réteg az adatbázis fülött (O/R mapping modellje), adatbázis motor független
-
2 féle módon létrehozható a mapping
- EDMX fájl (csak EF-ben) → EDM designer
- EDMX nélkül, kódból leírás → runtime EDM
-
csak EF-en:
- database first → van egy adatbázis, és abból generálódik az EDM
-
EF és EF Core is:
-
code first → kódból (c#) generálódik az adatbázis és az EDM is
-
verziókezelésnél ez macerás pl
-
fluent API-val
class MyDbContext : System.Data.Entity.DbContext { //adatbázist rerezentálja public DbSet<Product> Products { get; set; } //Products tábla public DbSet<Category> Categories { get; set; } //Categories tábla protected override void OnModelCreating(ModelBuilder modelBuilder) { //fluent API modelBuilder.Entity<Product>().Property(b => b.Name).IsRequired(); //Product-nak legyen egy Name property-je, amit közelezően meg kell adni modelBuilder.Entity<Product>().HasOne(p => p.Category).WithMany(c => c.Products); //Product-nak elgyen 1-több kapcsolata a Category-ról a Products-ra } } -
attribútumokkal
[Table("Product")] class Product { [Key] public int Id { get; set; } [Required] [StringLength(1000)] public string Name { get; set; } public VAT VAT { get; set; } public ICollection<Category> Categories { get; set; } }
-
-
-
Navigation property → adatbázis join automatikusan
- nem kell leírni a join-t, mert maga a fluent API-s vagy attribútumos leírás tartalmazza!
-
-
DbContext
-
adatbázis elérés központi osztálya
-
rajta keresztül indítható lekérdezés
-
nyilvántartja az összes entitást és rajtuk végzett módosítást → SaveChanges() menti az adatbázisba
- SaveChanges = tranzakcióba fogja menteni
-
rövid életciklusú → using-ba tegyük!
-
NEM szálbiztos! (mindig újat hozzunk létre!)
-
ne cache-eljünk vele
-
példányosított DbContext = nyitott adatbázis kapcsolat
-
kulcsok
- elsődleges kulcsot konvenció alapján találja meg → Id, ProductId
- más mezőnév használatakor jeleznünk kell azt →
[Key]vagymodelBuilder.Entity<Product>().HashKey(c => c.UniqueName); - összetett kulcs is lehet
- privát kulcs nélküli táblák → nem képezhetők le!
-
lekérdezés
- DbContext
- listát vezet az újonnan felvett és törölt entitásokról
- nyilvántartja az objektumokon történt változtatásokat
- nyilvántartja a lekérdezett entitásokat
- AsNoTracking() → ha csak lekérdezzük, és nem akarjuk módosítani azokat!
- hasznos, mert erőforrást spórolunk vele
- DbContext
-
új entitások beszúrása és mentése
- új entitás létrehozása, kulcs üresen hagyva →
var newEntity = new Class() - DbContext-hez rendelés
DbContext.DbSet.Add(newEntity)- entitáson kerüli hozzákötés →
someEntity.Property = newEntity
DbContext.SaveChanges()- EF lefuttatja az INSERT SQL utasításokat
- elsődleges és külső kulcsok bekerülnek a DbContext-hez tartozó entitásokba
- új entitás létrehozása, kulcs üresen hagyva →
-
entitások módosítása
-
tulajdonság módosítása
-
DbContext nyilvántartja a változtatást
-
SaveChanges() véglegesíti
-
példa
var course = context.Course.Single(q => q.Neptun=="VIAUAC01"); var aut = context.Department.Single(q => q.Code=="AUT"); course.Name = "Adatvezérelt rendszerek"; course.Department = aut; context.SaveChanges();
-
-
entitások törlése
-
csak betöltött entitás törölhető
-
DbSet.Remove(...), FONTOS hogy a zárójelbe NEM adható me LINQ lekérdezés! -
SaveChanges() véglegesíti
-
példa
var c = context.Course.Single(q => q.Neptun=="VIAUAC01"); context.Course.Remove(c); context.SaveChanges();
-
-
-
eager loading / lazy loading
- eager loading
- hivatkozás betöltésének kezdeményezése
context.Products.Include(entity => entity.NavProp)- egy SQL lekérdezésbe hozza az adatokat, de többet nem kell lekérdeznie
- lazy loading
- navigation property-k mentén a hivatkozott entitás betöltése amikor először használjuk
- olcsóbb lekérdezés az elején, DE hivatkozott entitás betöltésekor újabb lekérdezésbe fog ez kerülni
- alapból ez van bekapcsolva
- eager loading
-
entitás típusok
- EF esetén
- EntityObject (csak EF-nél) → ebből fognak származni az osztályok (picit sok felelőssége van!)
- POCO (Plane old CLR object) → egyszerűbb osztály legyen, egy felelősségük van
- változáskövetés nincs benne → összehasonlítgatással megy
- lazy loading támogatás nincs
- POCO Proxy → POCO + változáskövetés és lazy loading
- runtime generálódik a csúnya EntityObject szerű osztály
- ez az alap a rendszerben
- EF esetén
-
tranzakciók
- SaveChanges tranzakcionális
- explitic tranzakció indítása
context.Database.BeginTransaction()
-
tárolt eljárások (csak EF-nél)
- 2 módon:
- DbContext függvényeiként
- Entitások adatmódosító függvényeiként: Insert, Update, Delete
- 2 módon:
EF Core extrák¶
- DbContext.OnConfiguring → NE használjuk ha lehet
- adat konverzió, pl enum -> string
- migráció → C# kódból vezérelt adatbázis séma változtatás
- adatbázis létrehozása C# kódból:
dbContext.Database.EnsureCreated()(ilyet szabad code first modellből!)
MongoDB¶
- ez egy nem relációs adatbázis = NoSQL
Alap koncepciók¶
- motiváció, azaz a relációs adatbázis hátrányok
- fejlődő alkalmazás → bonyolult séma → nő az adatbázis (nehéz átlátni és karbantartani :( )
- folyamatos séma változtatás
- migráció
- teljesítmény problémák (konzisztenciából fakadóan)
- ötlet: hagyjuk el a szigorú sémát → NoSQL
- NoSQL-nek semmi köze az SQL-hez
MongoDB¶
-
rendszer architektúra (kliens-szerver)
-
logikai felépítés: klaszter > szerver > adatbázis > gyűjtemény > dokumentum
- klaszterezéssel osztjuk szét több gépen
-
dokumentum
{ name: "sue", age: 26, status: "A", groups: ["news", "sports"] }- JSON vagy BSON
- elemi tárolás egysége
- kulcs-érték párokat tárol
- kulcs: szabad szöveg lehet, nem kezdődhet $-el, _id implicit mező, caseSensitive
- objektum-orientált világban: objektum lesz a dokumentum
- méret limit: 16MB
-
gyűjtemény
- relációs adatbázis tábla analógiája
- nincs sémája, definiálni se kell, csak dobáljuk bele a dokumentumokat
- gyűjtemény = hasonló dokumentumok gyűjteménye (logikai szervezés, de nem kötelező)
- indexek definiálhatóak rá → gyorsabb keresés elérése miatt
- nincs tartomány integritás kritérium
- azaz lehet egyik dokumentumban több kulcs-érték pár mint a többiben
- és lehet az egyikben az age szám, míg a másikban string!
- DE minket ez utóbbi zavar majd :(
-
adatbázis
- alkalmazás adatainak összefogása
- jogosultságokat adatbázis szinten adhatóak
- caseSensitive ez is!
-
Relációs séma MongoDB tábla gyűjtemény rekord dokumentum oszlop (skalár) mező (skalár & összetett) VANNAK integritási kritériumok NINCSENEK integritás kritériumok kulcs ObjectId, unique index külső kulcsok hivatkozás _id alpaján join beágyazás, töbök tranzakciók ~tranzakciók (van, de más cucc) -
kulcs
- minden dokumentumban: _id (ezen kívül nem lehet saját kulcs!)
- 12 bájtos (időbélyeg, random bájt, számláló)
- globálisan egyedi
- egyedi azonosításra használjuk → _id
- egyedi biztosításra használjuk → index (szól ha ütközés van)
- összetett kulcs NINCS, DE összetett index van
- minden dokumentumban: _id (ezen kívül nem lehet saját kulcs!)
-
hivatkozás más dokumentumra
- beágyazás tömbként vagy hivatkozás → 1-több kapcsolat
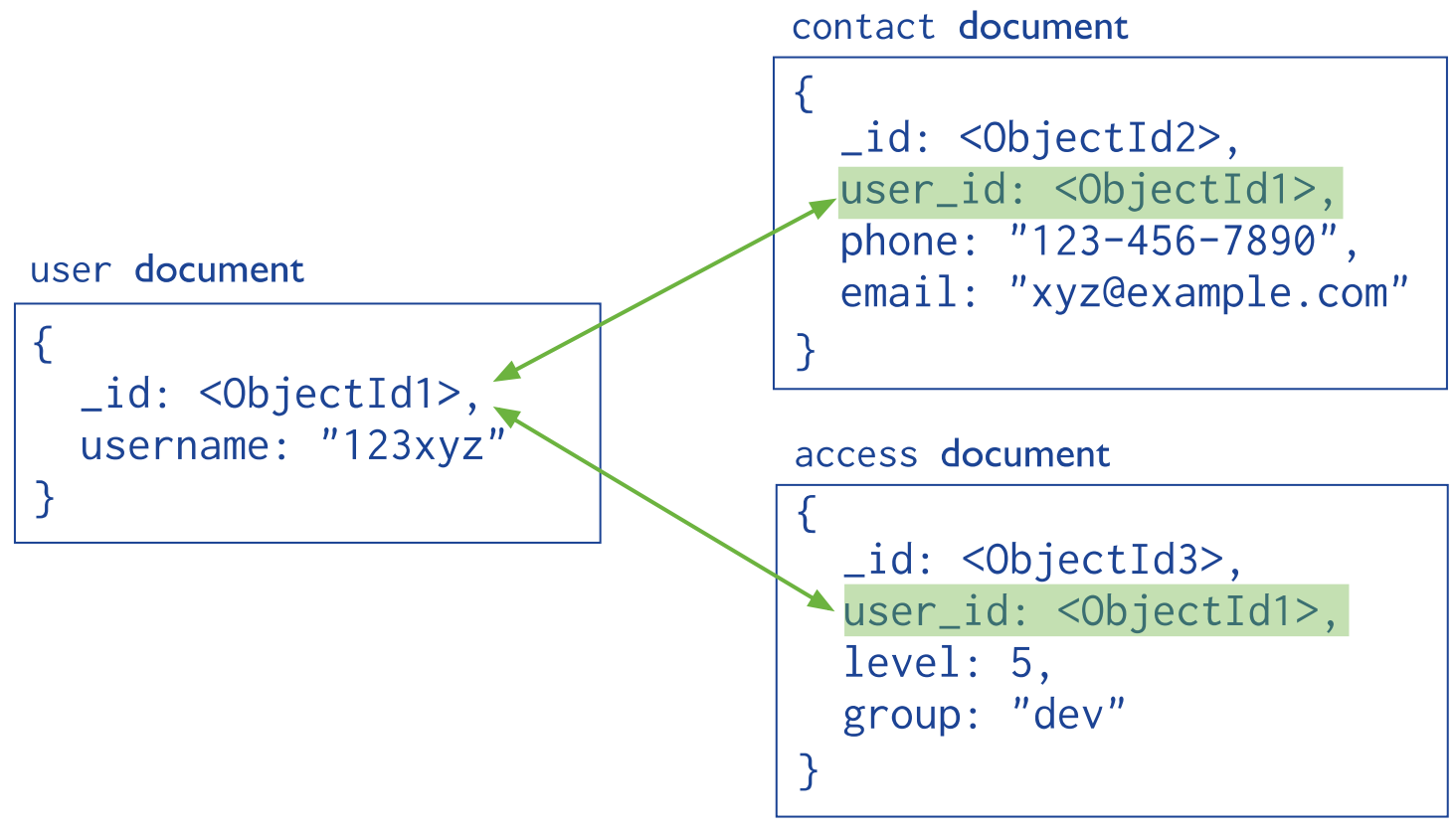
- normalizálás (beágyazás), join helyett → 1-1 kapcsolat

- beágyazás tömbként vagy hivatkozás → 1-több kapcsolat
-
tranzakciók
- alapvetően nem támogatott ebben a világban
- atomicitás van
- izoláció helyett → read/write concern

CRUD műveletek, lekérdezések¶
- "wire protocol": TCP/IP alapú bináris
- kérés-válasz egy JSON dokumentum
- C# elfedi majd nekünk
- mongoDB.Driver package-et kell hozzáadni
Használat .NET-ben¶
- ezt a jegyzetből kell kiolvasni
Séma tervezés¶
- gyűjtemények → általában egyértelműek
- beágyazást preferáljuk (ahol lehet)
- tranzakciók csak végszükség esetén
Lekérdezés optimalizálás célja¶
- időre optimalizálunk
- Válaszidő befolyásoló tényezői
- I/O költség
- ez a legmeghatározóbb
- Moore törvény nem igaz
- CPU használat
- komplex lekérdezéseknél, összetett számításoknál
- Memória használat → Cache hatása miatt
- I/O költség
- adatbázis végzi az optimalizálást
- statisztikák alapján
- költség becslés = válaszidő (CPU + I/O idő)
- triviális terv → ezeket NEM kell optimalizálni, mert az több idő lenne
- egyszerűbb lekérdezéshez egyértelműen generálható
- szabály alapú lekérdezési tervek
- ha nem készíthető triviális terv
- összetett optimalizálás
- fázis
- egyszerű szabály alapú átalakítások (hash join-t preferál)
- ha így már adott költség alatti, akkor végrehajtja
- fázis
- kibővített átalakítások
- ha így már adott költség alatti, akkor végrehajtja
- fázis → párhuzamos végrehajtás vizsgálata
- fázis
- összetett optimalizálás
- statisztikák alapján
- lekérdezés feldolgozás menete
- elemző (parser) → optimalizáló → sorfordító → végrehajtó
- elemző: szövegből logikai tervet készít (lekérdezés fordítása)
- optimalizáló: fizikai terv készítése, táblák bejárása és összekapcsolása
- sorfordító: I/O műveletekre leképzi
- végrehajtó: végrehajtja
- logikai végrehajtási terv
- elemző fa
- relációk (levél elemek)
- műveletek (csomópontok) pl join, szűrés
- descartes-szorzat, projekció, szelekció, összekapcsolás, ismétlődés szűrése, csoportosítás, rendezés
- adatok lentről fölfele "áramlanak"
- elemző fa átalakítása
- cél: optimális logikai terv kialakítása, fizikai végrehajtási terv keresési terének vágása
- alapkoncepciók:
- kiválasztás műveletek lefele mozgatása (szűrés lefele, hogy kevesebb adattal kelljen dolgozni!)
- join operátorok használata (direkt szorzatot kerüljük)
- join operátorok egyik attribútuma mindig tábla
- kiválasztások leírása a diasorban!
- elemző fa
- fizikai végrehajtási terv
- algoritmusok konkretizálása
- tervek szabály alapján vagy költségbecslés alapján
- join algoritmusok:
- nested loop join → egymásba ágyazott kettős for ciklus
- I/O költség → O(blokk_szám_1 * blokk_szám_2)
- tetszőleges méretű táblák esetén működik
- hash join
- kisebb reláció beolvasása
- vödrös hash építése a memóriában (kulcs a join operátorban szereplő oszlop)
- a nagyobbik reláció beolvasása, kapcsolódó rekordok keresése a vödrös hashben
- I/O költség → O(blokk_szám_1 + blokk_szám_2)
- negatívumok: el kell férnie a táblának a memóriában, csak egyenlőség alapon lehet keresni
- sort merge join
- mindkét reláció beolvasása a memóriába, majd rendezzük kulcs szerint
- összefésüljük a 2 listát
- kis méretű relációk esetén jó, index kell a rendezés miatt
- I/O költség → O(blokk_szám_1 + blokk_szám_2)
- nested loop join → egymásba ágyazott kettős for ciklus
- tábla elérési módok
- 2 kategória:
- teljes átvizsgálás → mindet felolvassuk a disk-ről (kis táblák esetén, ha minden rekordra szükség van)
- index alapú átvizsgálás → szűrés esetén, rendezés megvalósításakor
- table scan → ha nincs semmilyen index, szűrési feltételt is kiértékeli
- clustered index scan → nyalábolt adatolvasás
- adatblokkok index szerint rendezve (primary key mentén jön létre automatikusan MSSQL-ben)
- table scan helyett ezt preferálja!
- nonclustered index scan → =-ség jellegű kiértékelésekkor
- clustered/nonclustered index seek
- index scan-hez hasonló
- B*fa leveleinek bejárása kezdőemetől
- kisebb, nagyobb, between kiértékelésére
- covered index
- B*fa levelének bővítése oszlopokkal, nem kell kiolvasni a tényleges rekordot
- 2 kategória:
- indexek
- egyszerű, összetett, clustered (memórián is olyan sordban van, csak 1clustered index lehet)
- clustered és nonclustered index együtt → nonclustered mutat a clustered-re és az meg a disk-re
- nézetek is indexelhetőek MSSQL-ben
- lekérdezési tervek cach-e → plan cache
- ha ugyanolyan struktúrájú lekérdezés jön, és ha statisztikák nem változtak
- tárolt eljárásra előre vannak elkészített lekérdezési tervek
- itt megadhatjuk, hogy mire optimalizáljunk
- általános tanácsok
- statisztikák legyenek naprakészek (ne kapcsoljuk őket ki!)
- lekérdezés struktúrája
- gondolkodjuk az adatbázis fejébel
- többféleképp megfogalmazható dolgoknál
- minél egyszerűbben írjuk le, annál jobb!
- select * -ot kerüljük! (nem tudja kihasználni az indexelést)
- inkább join mint in / not in, exists / not exist
- exists helyett inkább in
- nézeteket kerüljük ha lehet
- kerüljük a vagy feltételeket → union all
- kerüljük az al-lekérdezéseket
- indexek
- sématervezéskor már gondoljunk erre!
- összetett indexnél a hierarchia számít
- matematikai műveleteket kerüljük, mert elronthatja az indexelést (price+10<100 helyett price<90 legyen)
- függvények használata
- select listában lehet
- where feltételben ne használjuk!
- MongoDB
- indexelés meghatározó (csak keresési célt szolgál, mivel nincs join)
- index típusok
- egyszerű & összetett
- unique index
- tömbök tartalmát is indexeli
- beágyazott dokumentumokat is indexeli
- indexet _id-n kívül létre kell hozni
- nem használ statisztokákat
- mindet elkezdi lehajtani, amelyik első 101db-ot visszaadja → azt fogja használni
- optimalizáló lépések
- szűrés előre mozgatás
- sklp és limit előre mozgatás (projekció elé)
- összevonás (limit+limit, skip+skip)
- van terv cache
- csak a struktúrája szerepel, hogy mire szűrtünk azt pl nem (csak a mezők neve, az érték nem)
- query.explain() → megmutatja a tervét