Adatvezérelt rendszerek¶
Adatelérési réteg¶
- adatelérési réteg feladata
- adatelérési absztrakció biztosítása (ne kelljen foglalkozni a konkrét adatbázis implementációval)
- konkurenciakezelés
Repository¶
-
adatforrás (adatbázis) és üzleti logika közt van
-
adatelérési rétegben vannak repozitory-k
-
entitásokkal doglozik (entitás = osztály, ami reprezentál egy terméket)
-
repozitory
- entitásonként vagy entitás csoportonként (pl termék és kategória)
- technikailag egy osztály, interfésszel absztraháljuk el
- 2 fajta művelet → CRUD (Create Retread Update Delete) műveletek, és egyéb bonyolultabb műveletek
- üzleti entitásokkal dolgozik (nem azzal ami az adatbázisban van)
- minden technológia-specifikus rész itt van bezárva → technológia és platform függő
-
példa:
class ProductRepository : IProductRepo { //CRUD műveletek: List<Product> List() { ... } Product FindById(int Id) { ... } void Add(Product entity) { ... } void Delete(Product entity) { ... } void Update(Product entity) { ... } //bonyolultabb műveletek: void AddProductToCategory (Product p, Category c) { ... } void StopSellingProduct(Product p) { ... } }
konkurenciakezelés¶
- itt nem mindig működnek az izolációs szintek (nem nagyon létezik a tranzakció fogalma itt)
- backend-hez közel még működhet, frontend-ből vissza már nem
- 2 fajta megoldás:
- pesszimista konkurencia kezelés
- feltételezzük, hogy problémánk lenne ebből a módosításból → kizárólagosság biztosítása az adathoz
- optimista
- többség úgyis csak olvas, írás miatt ritkán lenne ütközés, ha mégis akkor detektáljuk
- pesszimista konkurencia kezelés
Pesszimista konkurencia kezelés¶
- meg akarja akadályozni a konkurens módosításokat
- erre jók a tranzakciók, ha kapcsolatunk van az adatbázissal (csak rövid időre tarthatóak fel)
- üzleti logikában nyilvántartjuk az éppen módosító folyamatokat, a többit gátoljuk
- ezt nehéz jól csinálni, de lehet
- sorbarakjuk a módosításokat
Optimista konkurencia kezelés¶
- nézzük, hogy volt a probléma
- változások adatbázisba való visszaírásáig el tudunk menni
- probléma: valaki átírta az adatot
- rekord tartalom alapján döntünk
- rekord verzió (számláló vagy időbélyeg)
- teljes tartalomvizsgálat (módosítás előtti megegyezik e a mostanival)
- nehézség: meg kell őrizni a módosítás előtti tartalmat
- hátrány: implementálni kell az olvasós és mentős sql utasításokban!
ORM¶
- objektum-relációs leképzés
- feladat: üzleti logika és adatbázis közti leképzés
- üzleti logikában → OO modellezés, UML, design patterns, statikus adatt mellett folyamatok is vnanak
- adatréteg → E/K diagram, UML data modelling, csak statikus adatok
- leképzés → ORM = objektum-relációs leképzés
- problémák: eltérő koncepciók, öröklődés, shadow információk, kapcsolatok leképzése
Alapkoncepció¶
- osztály = tábla
- adattagok = tábla oszlopai
- kapcsolat = külső kulcs
Problémák¶
- összetett mezők → vásárló = cím(irányítószám, város, utca)
- megoldás1: vásárlóban implementáljuk az irányítószám, város és utca attribútumot
- megoldás2: külön táblát csinálunk cím néven, és külső kulccsal kötjük őket össze
- eltérő adattípusok
- dátumok nehezek
- string =? nvarchar(???)
- korlátokat kell kezelni!
- shadow információk
- pl id-k, időbélyegek (c#-ban a referencia azonosítja az adatot, üzleti logikába kb felesleges DE mégis kell)
- SOLID elvet sértünk vele! (több felelősségük lesz)
öröklés megvalósítása¶
- Probléma:
- Person → absztrakt osztály
- több implementációja van
- új funkció beépítése → új leszármazott keletkezik
- hierarchia leképzése egy közös táblába
- összes attribútum felsorolása a hierarchiát bejárvat
- típus → egy oszlopban kódolt érték, vagy IsCustomer, IsEmpolyee → diszkriminátor oszlop
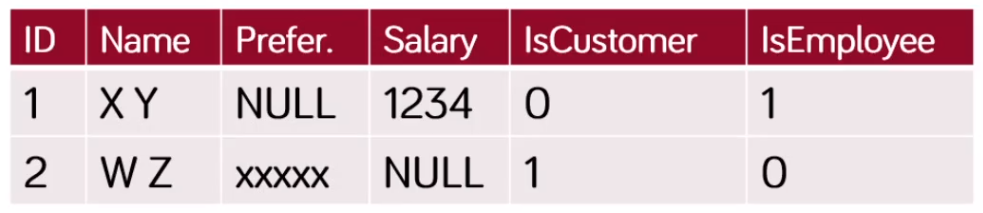
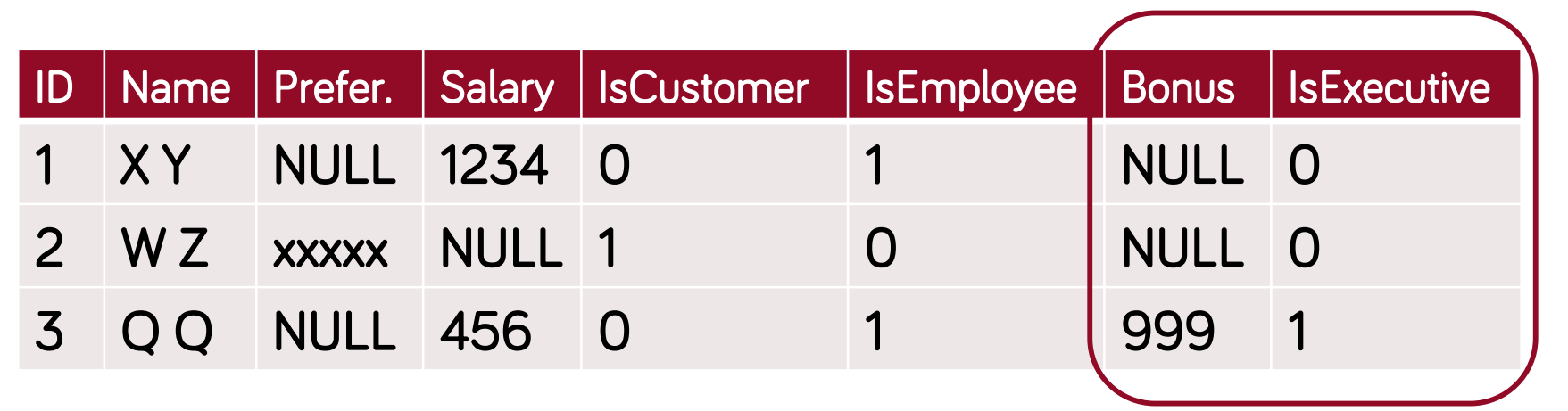
- előnyök:
- egyszerű, könnyű új osztályt bevenni
- objektum példány szerepének változása könnyen követhető (employee-ből executive lesz, vagy employee és customer egyszerre)
- hátrányok:
- helypazarlás, egy osztály változása miatt az összes tárolása megváltozik
- komplex struktúra esetén nehezen áttekinthető
- célszerű: egyszerű hierarchiák esetén
- valós osztályok leképzése saját táblába (akikből objektum példányok képződhetnek)
- osztályonként 1 tábla, abba az összes attribútum és ősöktől örökölt attribútumok eltárolása
- példányazonosító
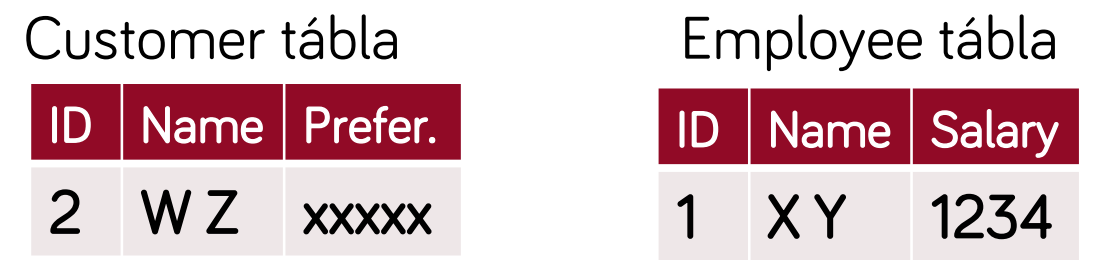
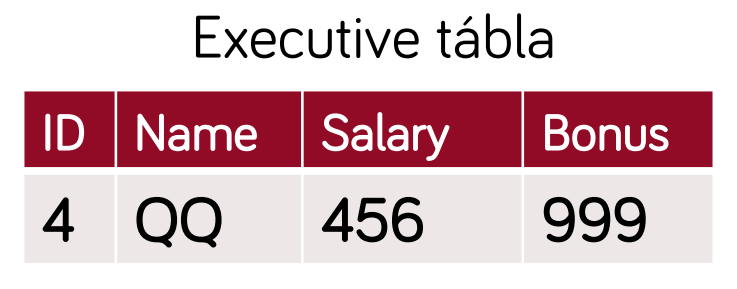
- előnyök:
- átláthatóbb, jobban illeszkedik az objektum modellhez, gyors az adatelérés
- hátrányok:
- egy osztály módosítása több táblát is érinthet, több szerepet betöltő vagy szerepet váltó példányok kezelése nehézkes
- célszerű: ritkán változó struktúrák esetén
- minden osztály leképzése saját táblába (absztrakt osztályok is)
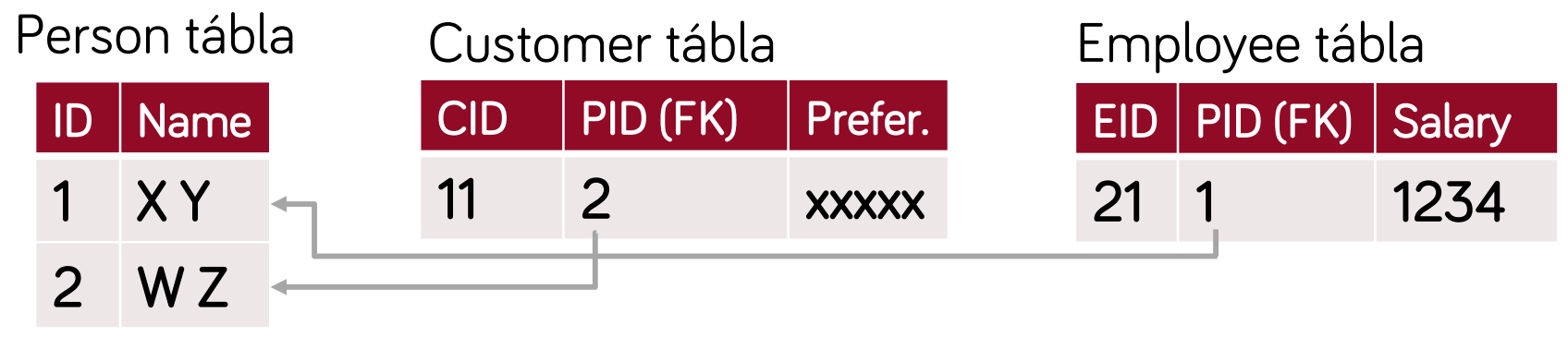
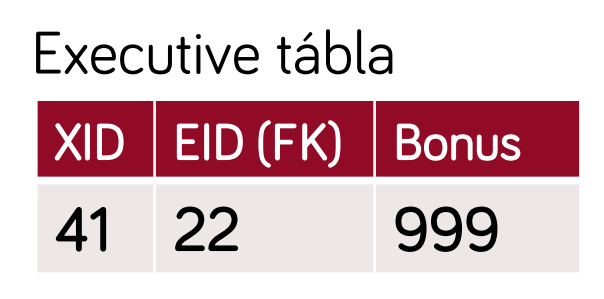
- előnyök:
- könnyű megérteni, könnyű módosítani a szülő osztályok struktúráját (customer-ben változtatás nem érint senki mást)
- hátrányok:
- összetett adatbázis séma = komplexebb
- egy példány adatai több táblában vannak → összetett lekérdezések, join-ok kellenek → lassabb
- célszerű: komplex hierarchia esetén, változó struktúra esetén
- osztályok és hierarchia szintek általános leképzése
- meta data driven megoldás
- általános séma
- tetszőleges hierarchai leírható, független a konkrét osztályoktól
- osztály hierarchai → meta adat
- osztály példányok → attribútumok manifesztálódása
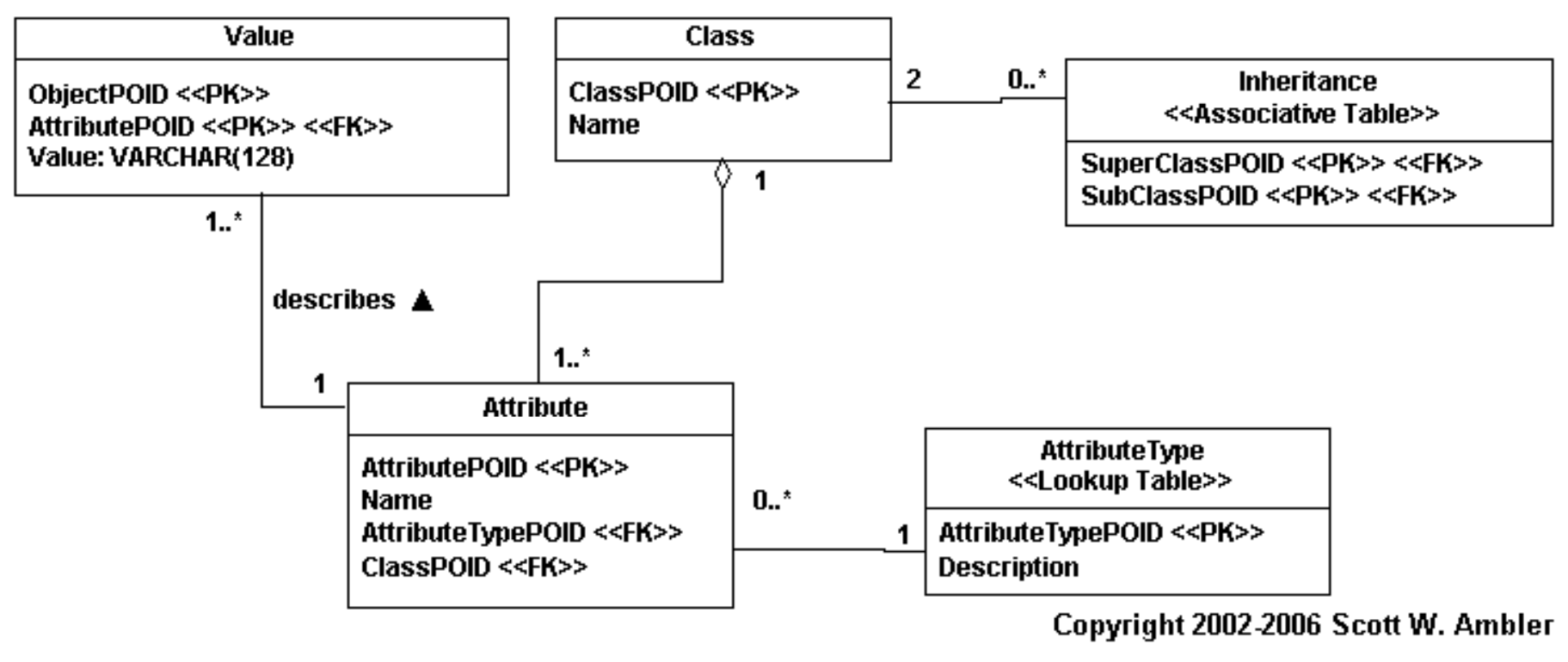
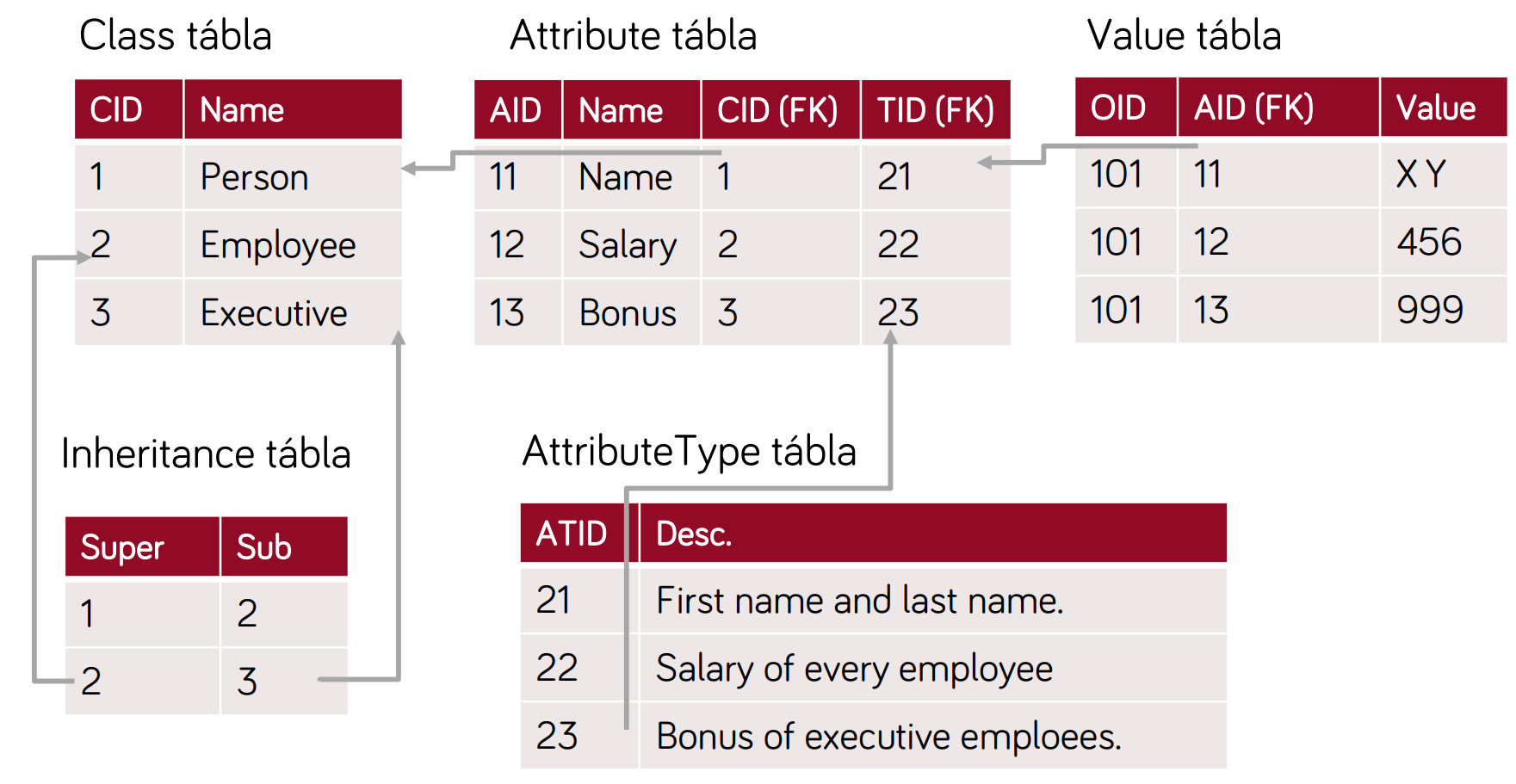
- minden érték a Value táblában van, az attribútum típus és osztály id-k külön helyeken vannak!
- előnyök:
- flexibilis → bármi leírható benne, sose kell új osztály!
- hátrányok:
- picit nehezen megérhető
- nehéz az egy osztályhoz tartozó adatok megtalálása
- nagy adatmennyiség esetén nem hatékony
- célszerű:
- komplex alkalmazásoknál (nemis tudjuk előre, hogy mit akarunk csinálni)
- kis mennyiségű adatok
- minden változhat futási időre (kívülről jönnek az adatok)
többszörös öröklés¶
- C++ miatt még mindig kell vele foglalkozni → eddig nézett módszerek ezt is meg tudják oldani :)
Objektum kapcsolatok leképzése¶
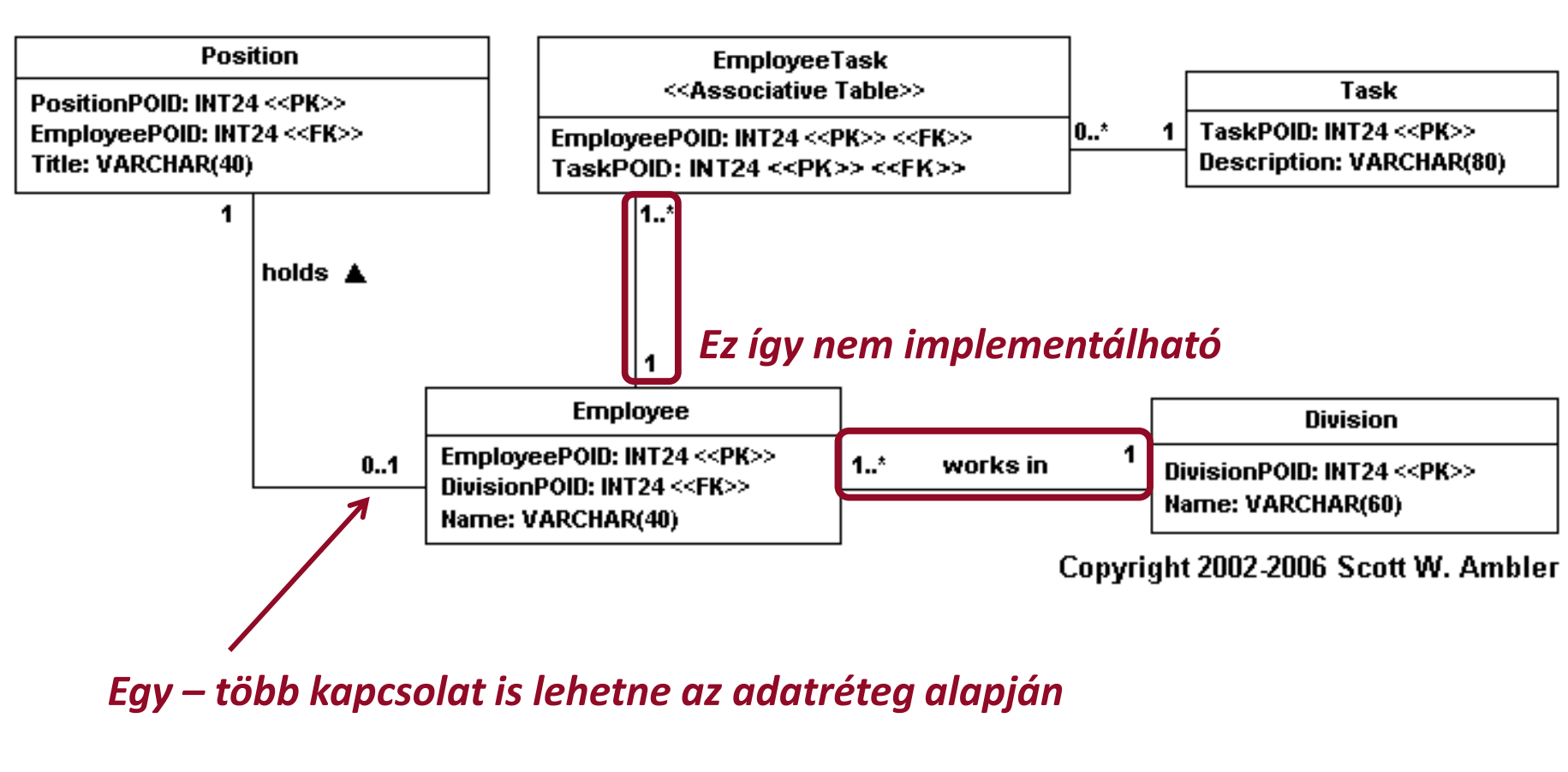
- kapcsolatok: asszociáció, aggregáció, kompozíció → referenciális integritás
- típusai: egy-egy, egy-több, több-több → referenciális integritás
- iránya: egyirányú, többirányú → NEM képezhető le :(
- egy-egy kapcsolat
- külső kulcs az egyik táblára (ettől még egy-több is lehetne)
- egy-több kapcsolat
- külső kulcs az "egy"-re
- több-több kapcsolat
- kapcsoló tábla használatával (két egy-egy kapcsolat)
- kardinalitás → nehezen leírható (nem kényszeríthető, hogy "rám" legyen hivatkozás!)
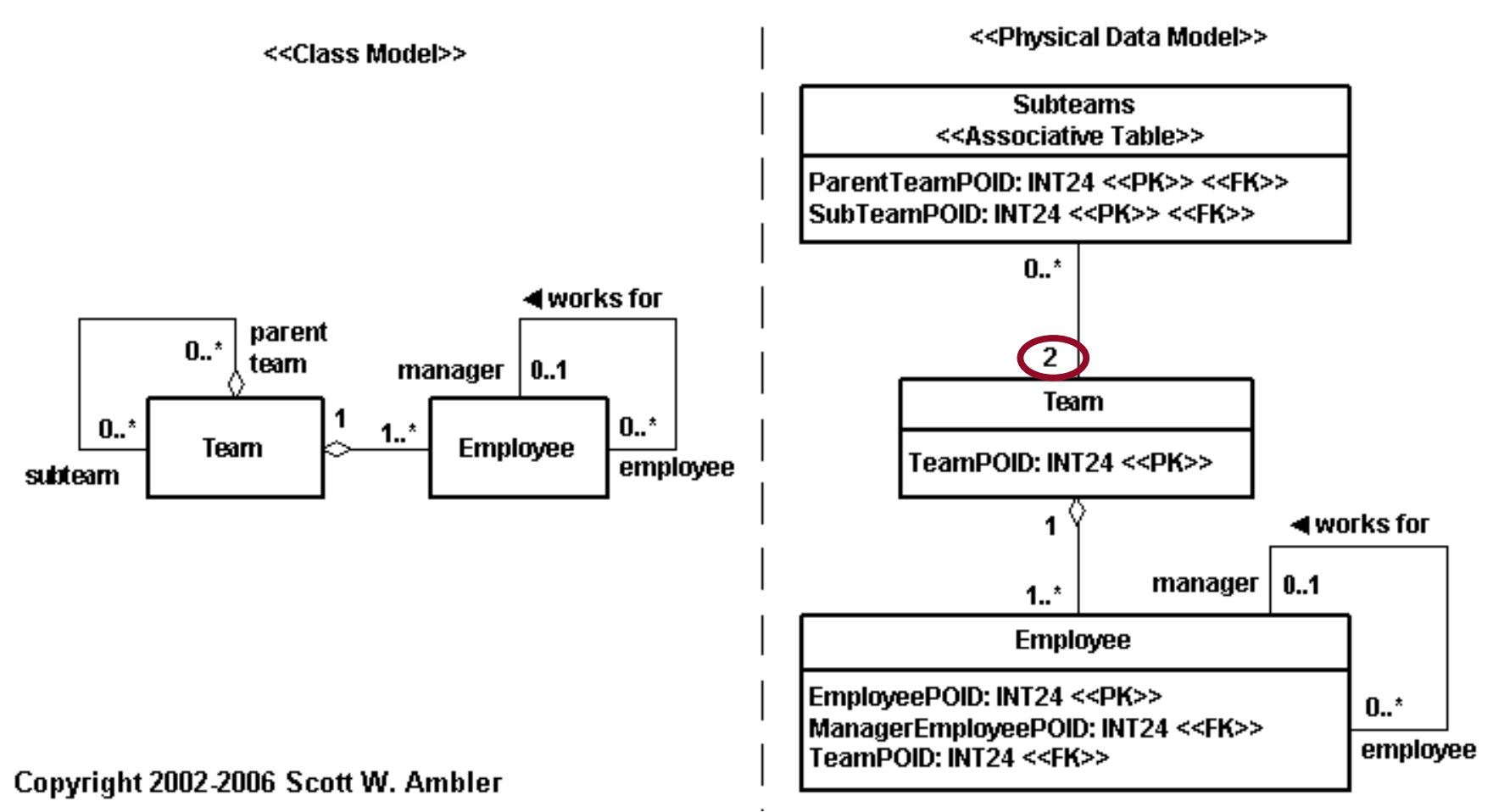
rekurzió (reflekxió)¶
- azaz önmagára mutató kapcsolat
rendezett gyűjtemények¶
- fontos: táblában NINCS sorrend, ezért külön attribútum kell nekünk (SequenceId)
- ez is shadow információ
- sorrendváltoztatás → több változik egyszerre!
- erre egy alternatív megoldás a hézagos felosztás (10-esével adom a sequenceid-ket)
osztály szintű tulajdonságok¶
- statikus adattagok → nem kötődnek példányhoz
- következő számla sorszáma
- kedvezmény értéke bizonyos összeghatár felett
- minden tulajdonságnak külön tábla
- gyors, sok kis tábla → bonyolít
- minden tulajdonság egy táblába
- elnevezése hülyeség lesz (global)
- gyors, egyszerű, DE állandó konkurenciaprobléma lesz
- NEM praktikus
- osztályonkéknt egy tábla az értékek különböző oszlopokba
- gyors, sok kis tábla → bonyolult
- általános megoldás
- egy táblába, sor szinten → minden tulajdonság új rekord (osztály, tulajdonság név, érték)
- adatkonverziót meg kell oldani :(
- egyszerű bővíteni → új tulajdonság = új rekord